[CS231n]Lecture07-Training Neural Networks part2
Lecture 07: Training Neural Networks part2
- 이 글은, Standford University 의 CS231n 강의를 듣고 스스로 정리 목적을 위해 적은 글입니다.
1. Fancier Optimization
1-1. Problems with SGD
- Loss function 의 gradient 방향이 고르지 못해, 지그재그 형태로 업데이트가 일어나고, 그 업데이트가 느리게 발생된다. 고차원으로 갈수록, 자주 만날 수 있는 문제.
- Local Minima & Saddle point: 높은 차원에서 생각해보면, Local Minima 는 고차원의 모든 gradient 방향에 대해 전부 loss 가 증가하는 방향이므로, 이 경우보다는 Saddle point 문제가 훨씬더 빈번하게 발생한다. Saddle point 의 경우 그 포인트 자체도 문제지만, 그 근처에서 gradient 가 매우 작기 때문에 update 를 해도 매우 느린 문제가 있다.
- SGD 의 S - stochastic! : 미니 배치의 loss 를 가지고 전체 training loss 를 추정하는 것이므로, 노이즈가 포함된 추정일 수 밖에없다.
1-2. 다양한 최적화 알고리즘 기법
최적화 알고리즘은 간단하게 정리한다.
- SGD, SGD + Momentum, Nesterov Momentum : 진행방향과 그 gradient (Momentum) 을 더해 실제로 업데이트 될 방향을 정한다.
- AdaGrad : 이전에 진행했던 gradient 를 제곱하여, 업데이트가 진행 될 수록 학습률을 작게해, 세밀하게 업데이트한다.
- RMSProp : AdaGrad 가 gradient 를 제곱할 때, 학습의 후반부에 갈수록 gradient 가 0 에 가까워 지게 되므로, 제곱하는 term 의 비율을 설정해 0으로 가는 것을 막는다.
- Adam : Momentum 방법과 AdaGrad를 합친 방법으로써, 학습률을 조절하면서, 속도를 조절하는 방법이다.
2. Regularization
2-1. Dropout
앞선 강의에서 다양한 Regularization 방법들을 살펴 보았었다.L2, L1, Elastic Net 등. 이번 강의에서는 신경망에서 자주 사용되는 dropout 방법을 살펴본다. Dropout 이란 forward 진행시, 일부 뉴런을 0으로 만들어 버리는 것을 말한다. dropout layer 는 우리가 그 dropout rate 을 설정하므로써, 어떤 확률로 꺼질지 설정할 수 있다. dropout 은 먼저 각 뉴런이 서로 동화되는 것을 방지함으로써 다양한 표현방식을 지닐 수 있게 한다. 또한, dropout 은 여러 sub model 을 앙상블 하는 효과를 낼 수 있다.
Dropout Layer 를 사용할 시 주의 할 점은 evaluation, inference 시, 네트워크의 출력에 dropout 확률을 곱해주어야 한다는 점이다. 혹은 test 시에는 기존 출력을 그대로 사용하고, train 할 때 dropout확률로 나눠주는 방법이다. (keras 에는 후자로 구현되어있는 듯 하다.)
p.s. Batch Normalization 에 regularization 의 효과가 있으므로, 일반적으로 BN 과 dropout 을 같이 사용하지는 않는다. 하지만 dropout 에는 우리가 조절할 수 있는 dropout rate 이 있는 장점이 있다.
2-2. Data Augmentation
신경망은 기본적으로 데이터가 많으면 많을 수록 학습에 유리한 이점이 있다. 따라서 우리가 가지고 있는 데이터를 조금씩 변형하여, 학습 데이터를 늘려주는 방법을 사용할 수 있다. horizontal flip이나, 사진에 일부분을 자르는 방법, Color jittering(이미지의 contrast, brightness 를 변형해준다)
2-3. Drop Connect
Activation 이 아닌, weight 을 확률적으로 0을 만들어 주는 방법
2-4. Fractional Max Pooling
고정된 Pooling window 를 랜덤으로 정하는 방법. 자주 사용되지는 않는다.
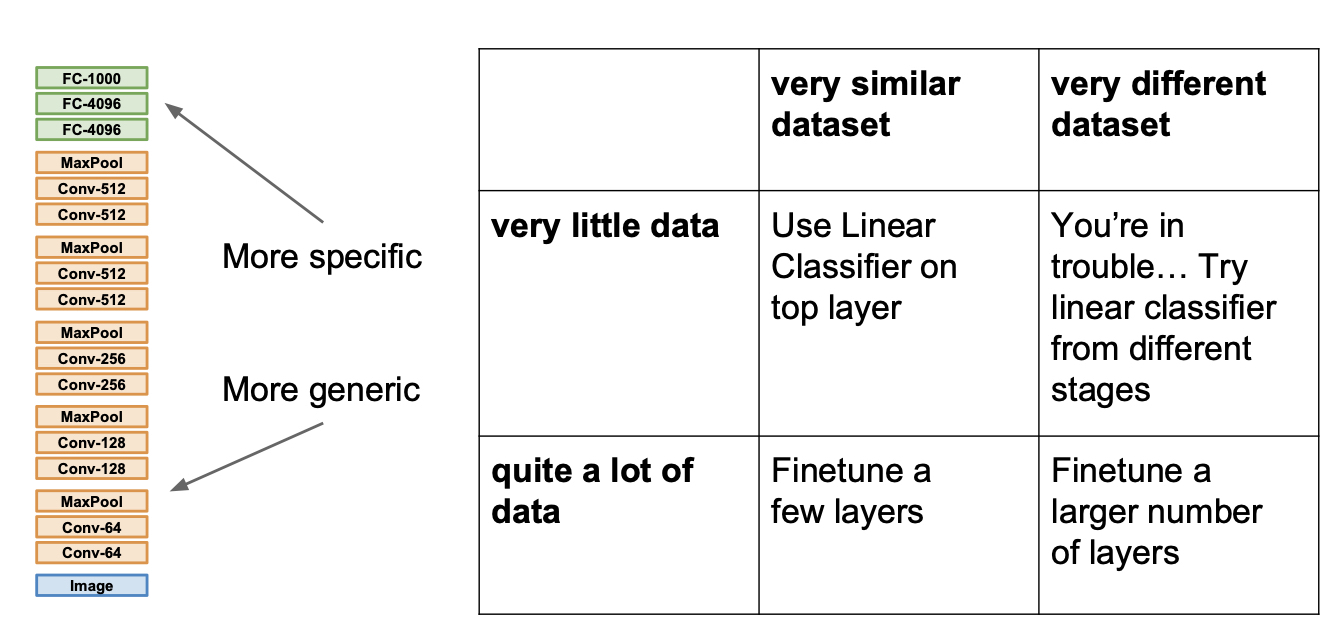
3. Transfer Learning
유명한 모델과 깊은 네트워크는 대부분 많은량의 데이터와 많은 하드웨어 Resource와 시간이 투입되서 구축된다. 우리가 이 모델구조를 가져와 우리의 목적에 맞게 사용하려고 보면, 우리가 가지고 있는 데이터와 자원의 한계로 학습에 실패하거나 그 시간이 매우 오래 걸리곤 한다. Transfer Learning 은 기존에 학습되어있는 모델 구조와 그 weight 을 가져와, 마지막 Fully Connected Layer 를 우리의 task 에 맞게 수정하고 이 부분만 학습하는 개념을 말한다.
4. Reference
[CS231n]Lecture07-Training Neural Networks part2
https://emjayahn.github.io/2019/07/22/CS231n-Lecture07-Summary/