[Study] Reinforcement Learning Basic
Lec1 Intro to RL
1. About Reignforcement Learning
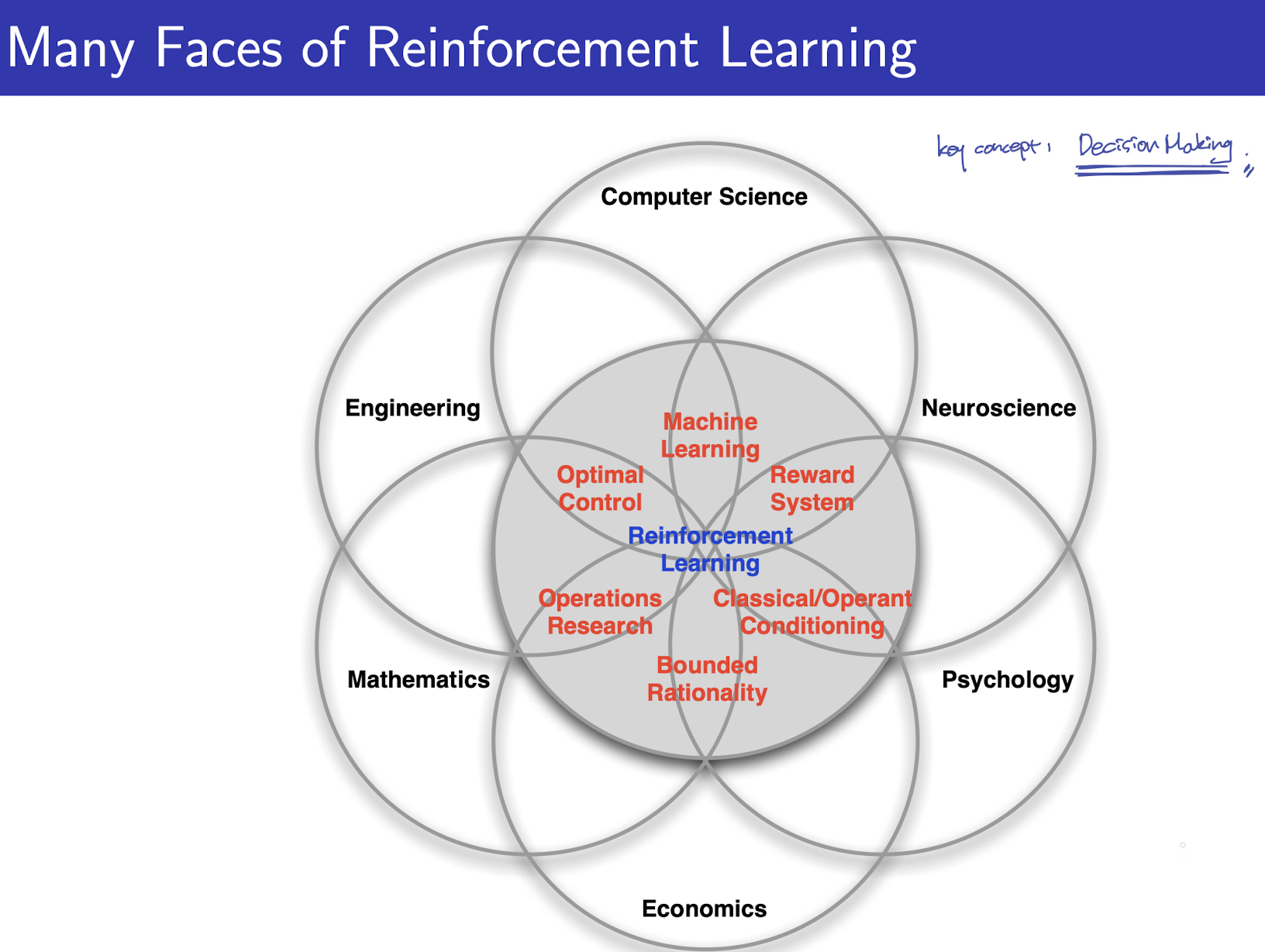
1.1 다양한 분야에서의 강화학습
다양한 분야에서 RL과 같은 혹은 비슷한 개념의 연구와 시도가 계속 되고 있습니다. 여기서 서로 다른 분야라 할지라도 공유되는 핵심 Key Concept은 “Decision Making” 입니다.
1.2 강화학습의 특징
- No supervisor, but reward signal
- 덧붙이자면, 흔히 지도학습(supervised learning)에서는 우리가 제공하는 정답 데이터와 설계한 Loss Function을 이용해 모델에 Feedback을 주지만, 강화학습에서는 정답이라는 데이터를 제공하지 않은채, Agent 의 Action 에 대해 “오구 잘했어 5점”, “그건 좀 별론데? 1점” 과 같이 reward 로 feedback 을 제공합니다.
- Delayed Feedback, Not instantaneous
- Agent 의 지금의 결정(action)이 좋았는지/나빴는지가 몇 스텝 후에 나온다는 것이 특징입니다.
- Sequential, not i.i.d data
- (FYI) i.i.d : independent identical distribution (Random Variable 의 독립, 동일 확률분포)
- 강화학습의 데이터는 시계열적인(Sequential) 데이터
- Agent’s actions affect the subsequent data
- Agent 의 행동이 reward와 received data 에 영향을 줍니다.
- EX) 로봇이 움직일 때마다 로봇이 보는 화면과 reward가 각각 달라집니다.

2. The Reinforcement Learning Problem
2.1 Rewards
- reward $R_t$ : scalar feedback signal
- 시간 t 에서 agent 의 action (or 선택)이 얼마나 잘 한 것인지 나타내는 피드백 신호
- agent의 목표 : 누적 reward의 최대화 (maximise cumulative reward)
- RL 은
reward hypothesis위에서 이루어진다
- Reward Hypothesis
- All goals can be described by the maximisation of expected cumulative reward
- 모든 목표는 누적 reward의 기댓값을 최대화 하는 것으로 잡을 수 있다. (아직 구체적으로 느낌은 오지 않음.. 과연 그런가..?)
2.2 Sequential Decision Making
- RL 은 결국 sequential decision making 이라고 표현 될 수 있다.
- sequential : 매 순간 t 에 대해서
- decision making : agent 의 action 을 선택하는 과정
- Agent의 Action 은 그 결과가 즉시 나오지 않을 수 있다. (may have long term consequences)
- Action 에 대한 Reward 역시 즉시 나오지 않을 수 있다. (reward ma be delayed)
- 지금, 이순간의 reward를 포기하고, long-term reward를 더 크게 하는 방향의 선택이 좋을 수 잇다.
- (Ex) Financial investment (take months to mature), refuelling a helipcopter (prevent a crash in several hours), blocking opponent moves (help winning chances many moves from now)
2.3 Agent and Environment
- ‘뇌’로 묘사되는 것이 Agent
- Our Goal: build on agent/algorithm
- Agent decides Action (EX: 모터의 Torque를 어떻게 설정할지, 로봇이 어떻게 움직일지 등)
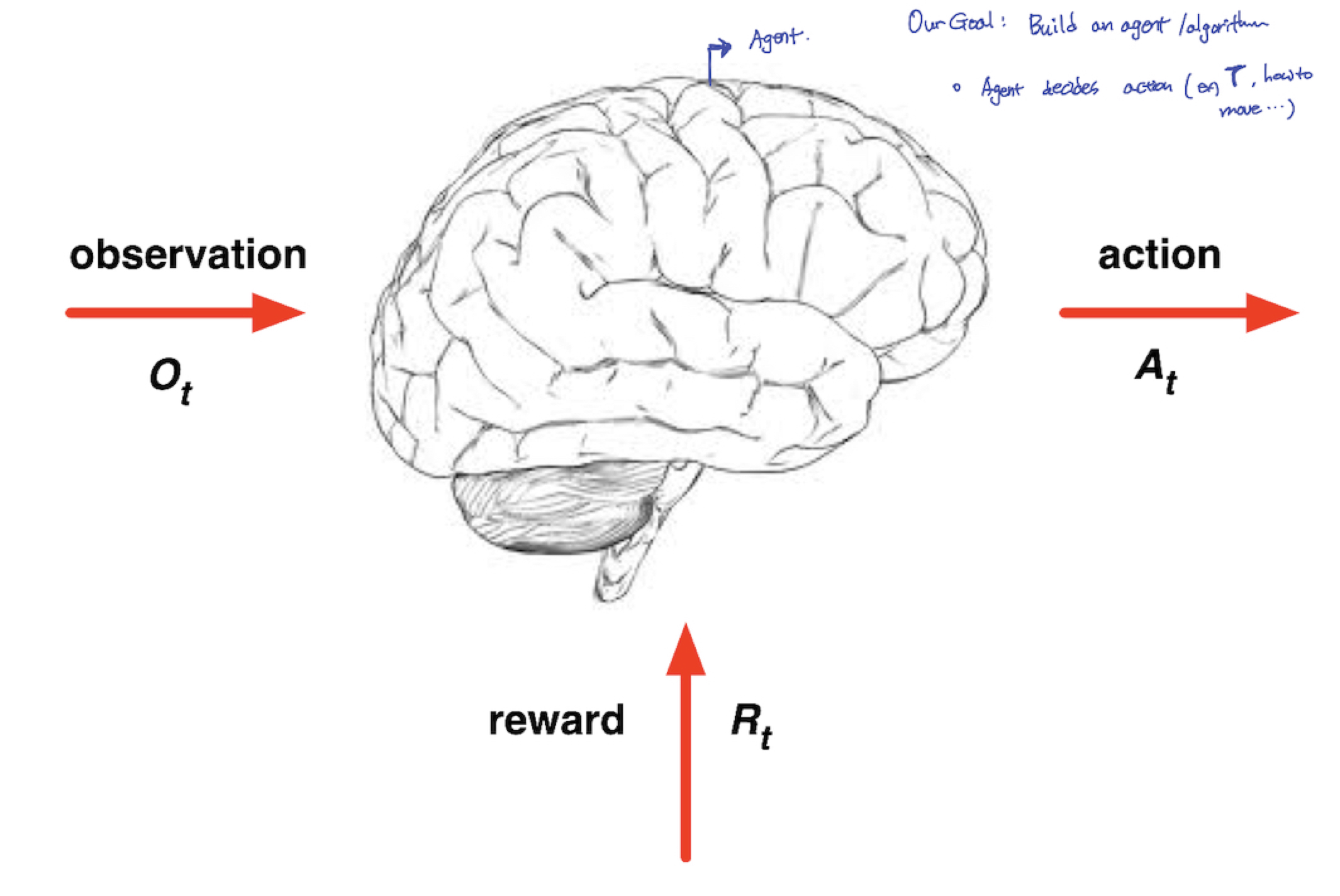
- ❗️매 Step t 마다❗️
- Agent는
- action $A_t$ 를 수행
- observation $O_t$ 를 받음
- scalar reward $R_t$ 를 받음
- Environment는
- agent 가 수행한 action $A_t$를 받음
- a에 대해 observation $O_{t+1}$ 로 반응
- a에 대해 scalar reward $R_{t+1}$ 로 반응
- t + 1로 다음 스텝 증가
2.4 History and State
HISTORY
- DEFINITION: observation 과 action, rewards의 sequence
$$
H_{t}=O_{1}, R_{1}, A_{1},…, A_{t-1}, O_t, R_t
$$- ❓Q❓: 위의 정의에서 보면, $R_{t}, O_{t}$ 의 경우 $A_{t}$에 대한 reaction 입니다. 따라서 Ot, Rt가 나타나기 위에서는 At가 반드시 선행되어야 하는것 같은데, time step t 에서의 history Ht는 At 가 빠져있습니다. 왜일까요? Ot, Rt → At 가 순서이면 make sense 할 것 같습니다만;;
- Next step by current history:
- agent의 action
- environment 가 observation 과 reward를 결정
State
- DEFINITION: 다음 step 에 어떤 것을 할지 정하는 정보
- 보통, Function of History
$$
S_{t} = f(H_{t})
$$
- Agent는
2.5 State
- Environment State: $S_{t}^{e}$
- David Silver “Information in the environment to determine what happens next”
- Environment’s private representation
- 보통 Environment State 는 agent 에게 보이지 않는다
- Environment State 가 agent 에게 보인다 할지라도, irrelevant information 일 가능성이 크다
- Agent State: $S_{t}^{a}$
- $S_{t}^{a} = f(H_t)$ : Funtion of History
- RL algorithm에서 사용될 agent에 관한 정보
- Information State (=aka Markov State)
History 로부터 얻게되는 모든 유용한 정보
A state $S_{t}$ is Markov:
Definition:
$$
P[S_{t+1}|S_{t}] = P[S_{t+1}|S_1, …, S_{t}]
$$Markov Property의 핵심은
- “미래의 State 는 현재 State에만 영향을 받는다”
- “미래의 State 는 과거 모든 State에 대해 독립적이다”
- Store ONLY current State (현재의 State가 이전의 history 정보를 담고 있으므로. RL 과 memory, Dynamic Programming 과의 연관성을 intuitively 이해할 수 있음)
- 헬리콥터 예제) 헬리콥터가 지금 바람을 맞을 때, 10분전 헬리콥터가 어떤 velocity 와 어떤 position 에 있었는지 중요하지 않다
2.6 Fully Observable Environments & Partially Observable Environments
Full observability : agent 가 directly environment state를 확인 할 수 있는 환경
- environment state = agent state = information state
$$
O_t=S_{t}^{a}=S_{t}^{e}
$$- 보통 위 state 들은 Markov Decision Procee (MDP)
Partial Observability : agent가 indirectly environment state 를 확인 할 수 있는 환경
- agent ≠ environment state
- 보통 이를, Partially observable Markov Decision Process (POMDP) 라고 한다.
- 이 경우, agent 는 자신의 state representation $S_t^{a}$ 를 정해야한다. 다음은 경우에 따라 $S_t^{a}$를 정하는 방식이다.
- Complete History 의 경우 : $S_t^{a}=H_t$
- Beliefs of environment state (Baysian Approach) : $S_t^{a} = (P[S_t^{e}]=s^1, …, P[S_t^{e}]=s^n)$ - Vector Probability에 의해 agent 의 next step 이 결정된다
- Recurrent Neural Network (Probability를 사용하지 않고, 단지 agent에 숫자만 넣어주면 된다는 생각으로 network를 사용할 수 도 있다.) : $S_t^{a} = \sigma(S_{t-1}^{a}W_{s}+O_{t}W_{o})$
MDP 와 POMDP 를 추후에 본 강의에서 다룰 수도 있겠지만, 그 내용의 중요도와 본 수업의 진행 방식에 따라 아래 강의도 함께 진행해도 좋을 것 같습니다.
https://www.youtube.com/watch?v=uHEjez97BvE
3. Inside an RL Agent
3.1 Major Components of an RL Agent
- Policy : Agent의 행동함수(behavior function)
- Value function : 각 state 와 action 이 얼마나 좋은지 나타내는 함수 (how much reward do we expect to get)
- Model : Agent 관점에서 바라보는 environment (agent’s representation)
- 위 세가지가 항상 모두 필요한 것은 아닙니다. 경우에 따라, 필요에 따라 구성하게 됩니다.
3.2 Policy
- Policy : Agent의 행동함수
- Map from state to action
- Policy 의 종류
- Deterministic Policy: $a = \pi(s)$ - argmax
- Stochastic Policy: $\pi(a|s) = P[A_{t}=a|S_{t}=s]$
3.3 Value Function
- Value Function : Prediction of future Reward
- State 1 or 2 / Action 1 or 2 를 선택할 때의 기준이 됩니다.
- $v_{\pi}(s)=E_{\pi}[R_{t+1}+\gamma R_{t+2}+\gamma^{2}R_{t+3}+…|S_{t}=s]$ ($\gamma$: discount factor - 더 먼 미래의 예측 reward 효과를 감소시키기 위함)
3.4 Model
Model : Environment 의 행동을 예측 (Agent 의 관점에서의 행동방식이지, 실제 environment 의 행동방식이 아님)
Transition Model $P$ : $P$ predicts the next state
$$
P_{ss’}^{a} = P[S_{t+1}=s’|S_t=s, A_t=a]
$$Reward Model $R$ : $R$ predicts the next (immediate) reward
$$
R_s^{a}=E[R_{t+1}|S_t=s, A_t=a]
$$
(Q) Trasition Model의 경우, Agent 관점에서 (Environment? ) state 를 예측 하는 것이라면, Policy 와의 역할 차이는 무엇일까? Policy와 Value Function 을 통해 agent 의 action 이 결정되고, 결정된 현재 action 에 의해 다음 state가 결정된다. 이렇게 볼때 Transition Model 과 Agent 간의 연결고리? TransitionModel과 Policy 간의 관계가 어떻게 되는지? Reward Model 도 마찬가지.
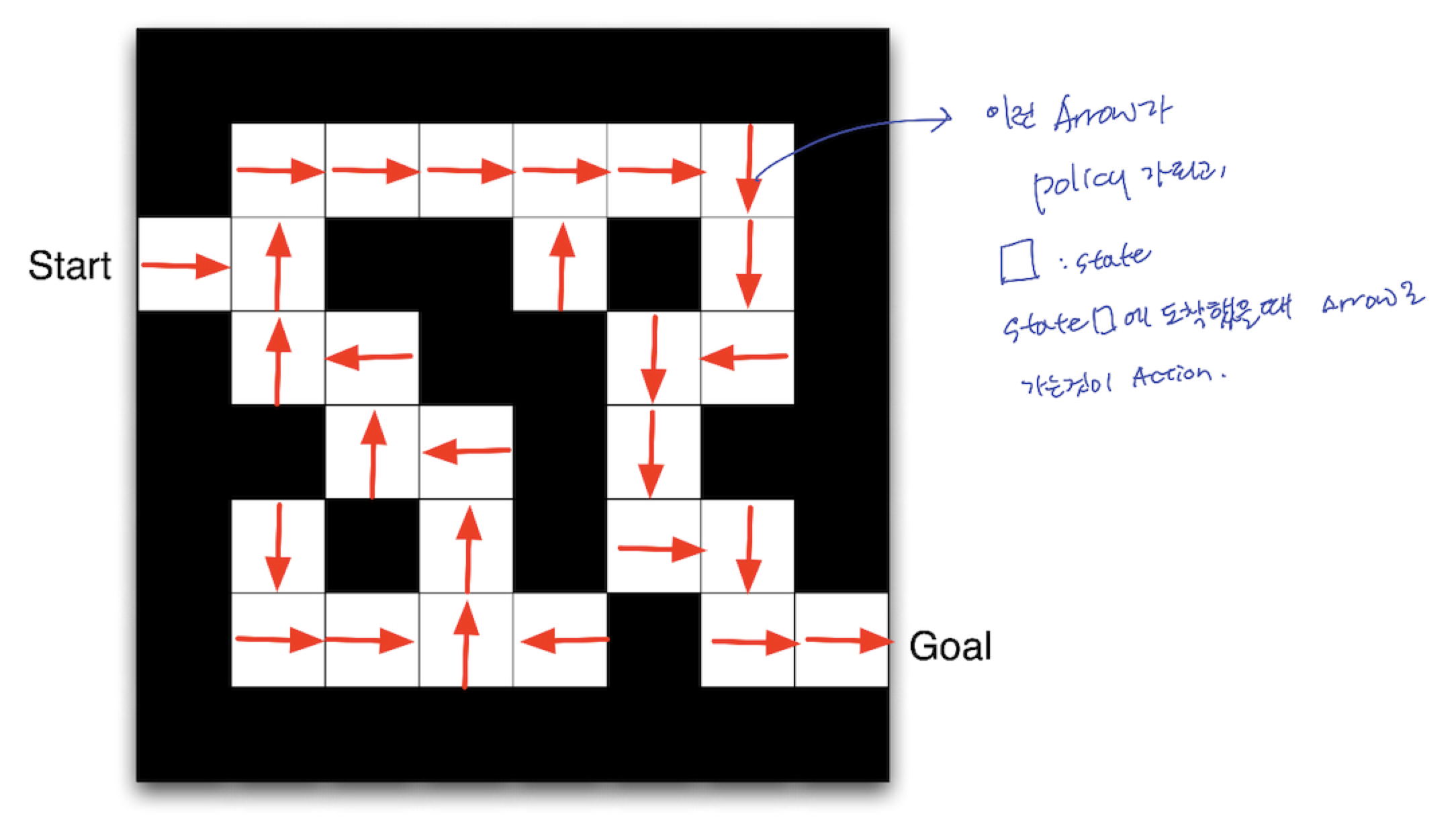
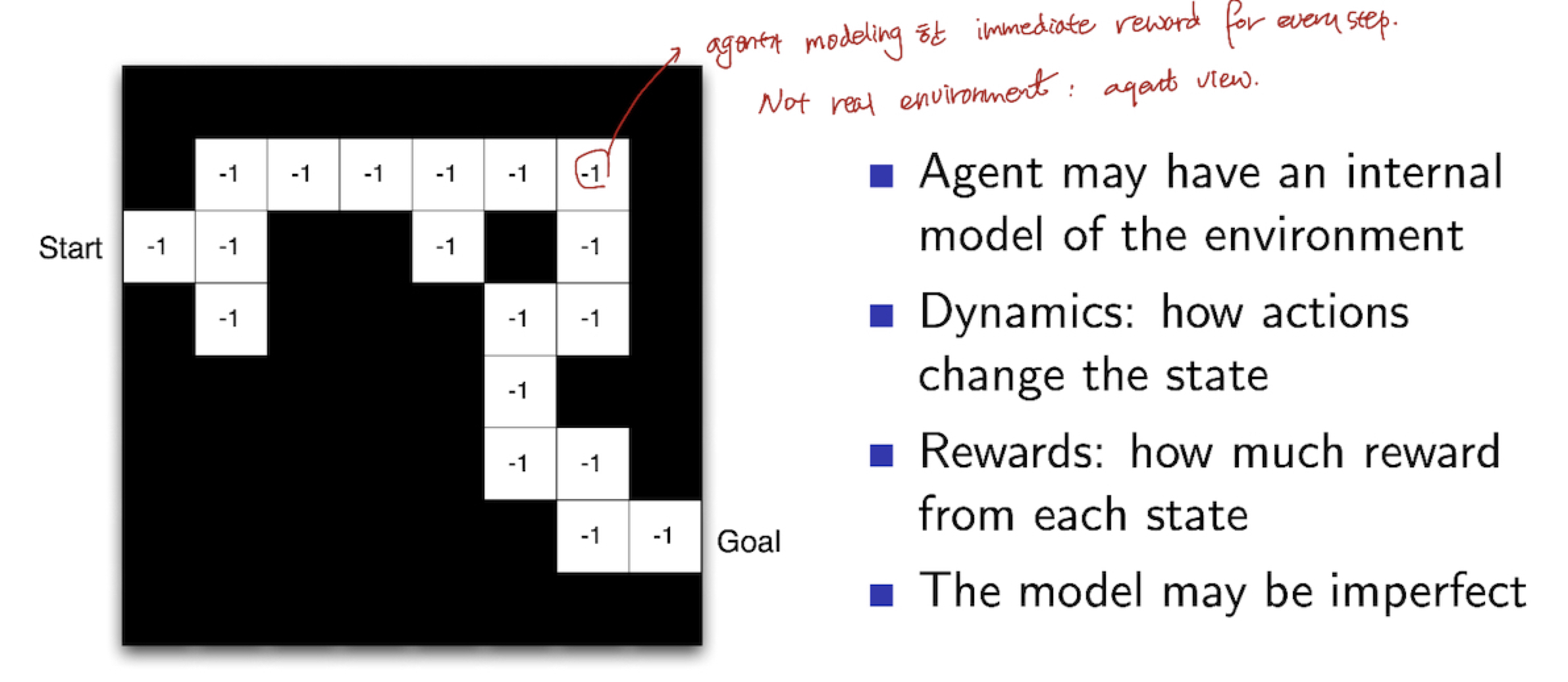
3.5 Maze Example
- Policy
- 아래 그림에서, 화살표→를 Policy라 생각할 수 있습니다.
- ⬜️ 를 state 라 생각할 수 있습니다.
- Agent 가 특정 ⬜️ 에 도착했을 때, → 를 따라 이동하는 것이 Action 이라 생각할 수 있습니다.
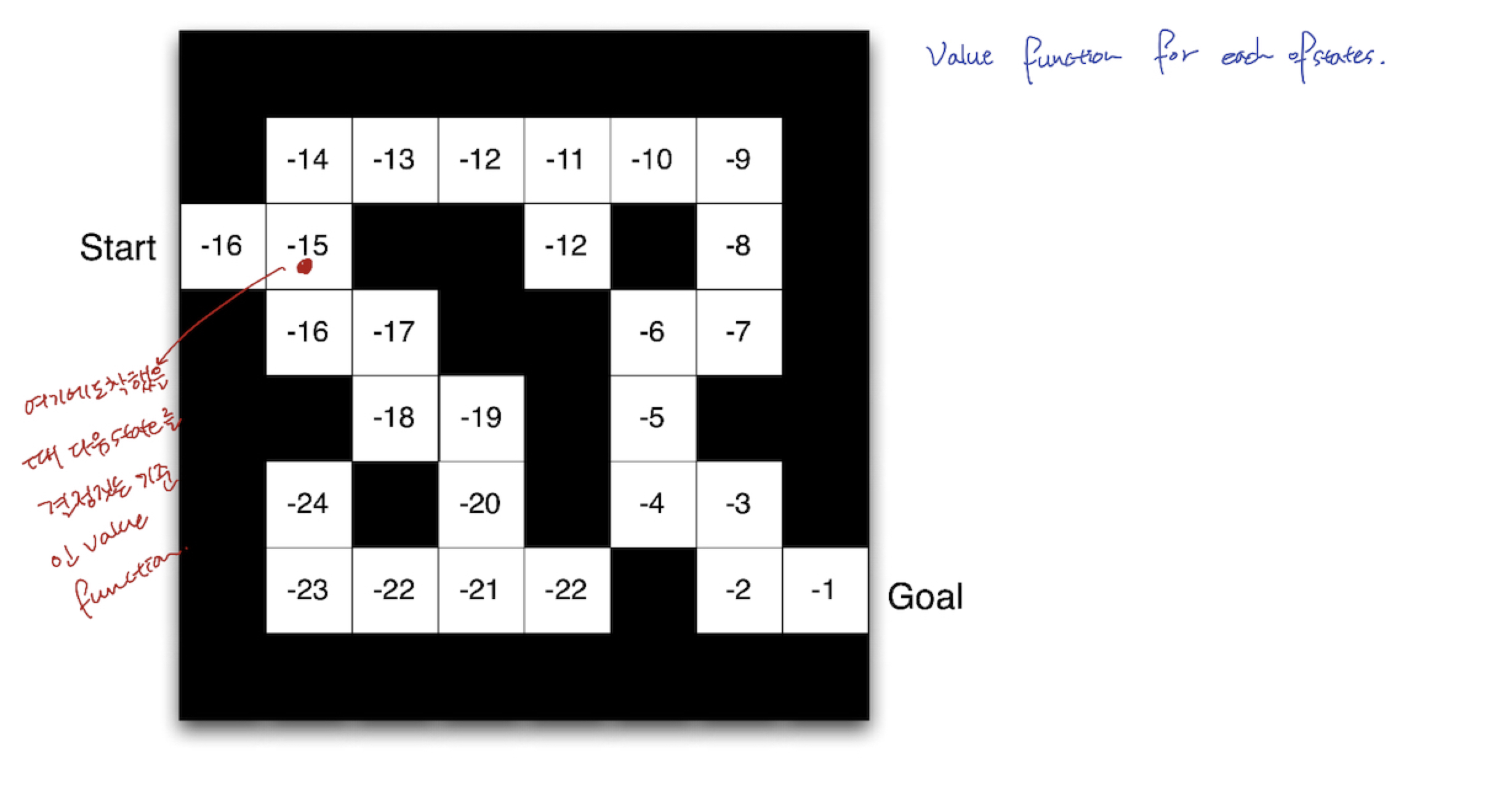
- Value Function
- 아래 그림은, 각 state 마다 value function 값을 적어놓은 것입니다.
- 특정 ⬜️ , 즉 state 에 도착했을 때, 다음 state(다음 action)을 결정 짓는 기준이 됩니다.
- $v_{\pi}(s)$
- Model
- Agent가 Modeling 한 immediate reward (실제 environment 가 아님)
- Dynamics : Action이 State 를 어떻게 변화 시키는지 (Q) 갑자기 어디서 튀어나온 terminology이죠? 강의 부분에서도 크게 언급을 안하였는데 Definition 처럼 표기를 해놨네요. Model 은 두가지라며…
- Rewards : 각 state마다 얼만큼의 reward 를 받는지
- ** The Model may be IMPERFECT
- Grid Layout : Transition Model $P_{ss’}^{a}$
- Numbers : Reward Model $R_s^{a}$
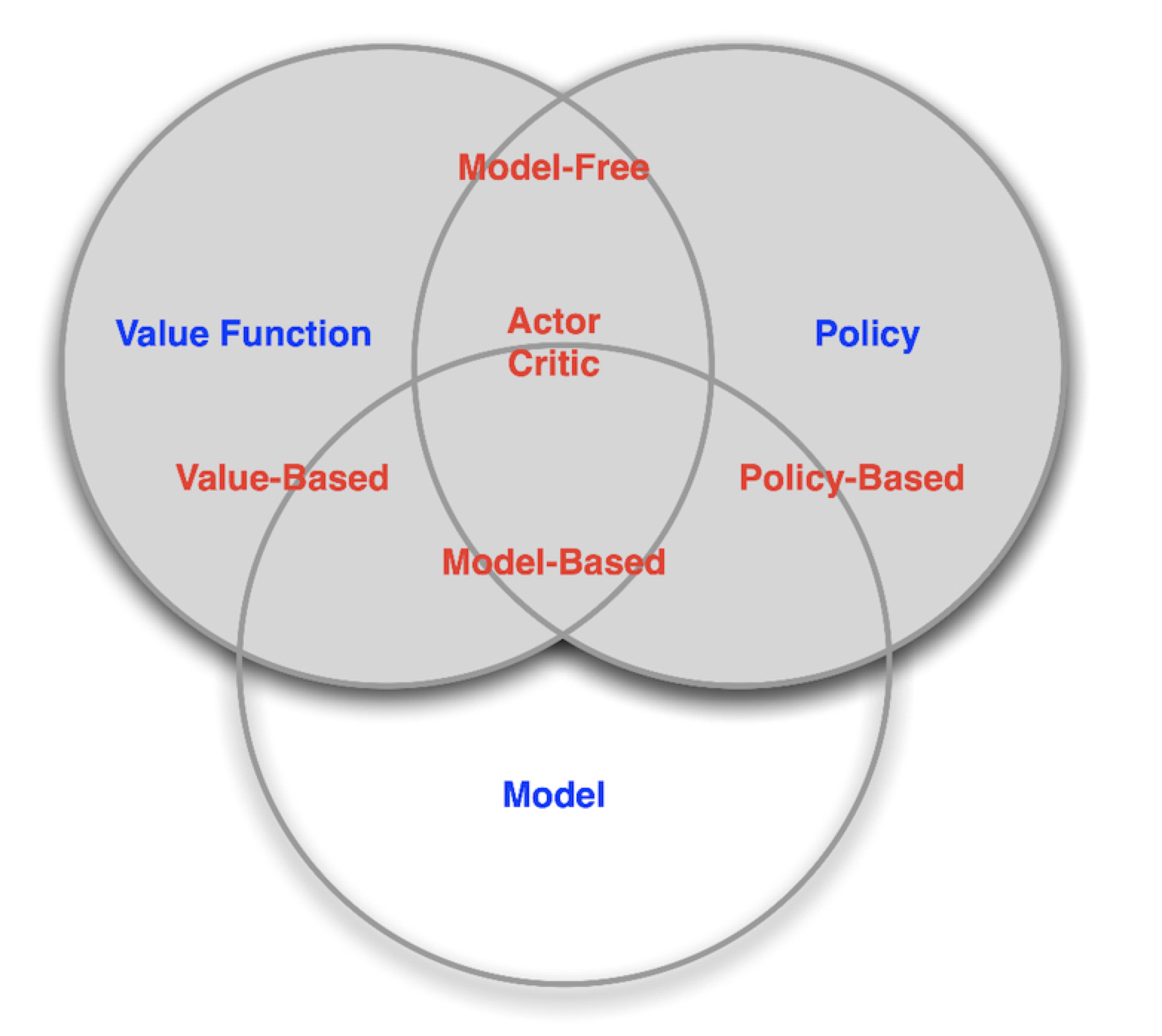
3.6 Categorizing RL agents
[Category 1] : RL Components(RL 구성요소) 중 Policy 와 Value의 저장 여부에 따라 다음과 같이 나뉩니다.
- Value Based
- No Policy
- Stores only Value Function
- Policy Based
- Stores only Policy
- No Value Function
- Actor Critic : Will cover Soon
- Stores both Policy and
- Value Function
[Category 2] : RL Components(RL 구성요소) 중 Model의 유무에 따라 다음과 같이 나뉩니다.
- Model Free
- Policy and/or Value Function 의 유무는 크게 중요하지 않으나 (어느 하나라도 있으면 됨),
- No Model
- Model Based
- Policy and/or Value Function의 유무는 크게 중요하지 않으나 (어느 하나라도 있으면 됨),
- Model
4. Problems within Reinforcement Learning
4.1 Reinforcement Learning Problem & Plannning Problem
- Sequential Decision Making에서 2가지 Fundamental Problem이 있습니다.
- Reinforcement Learning Problem
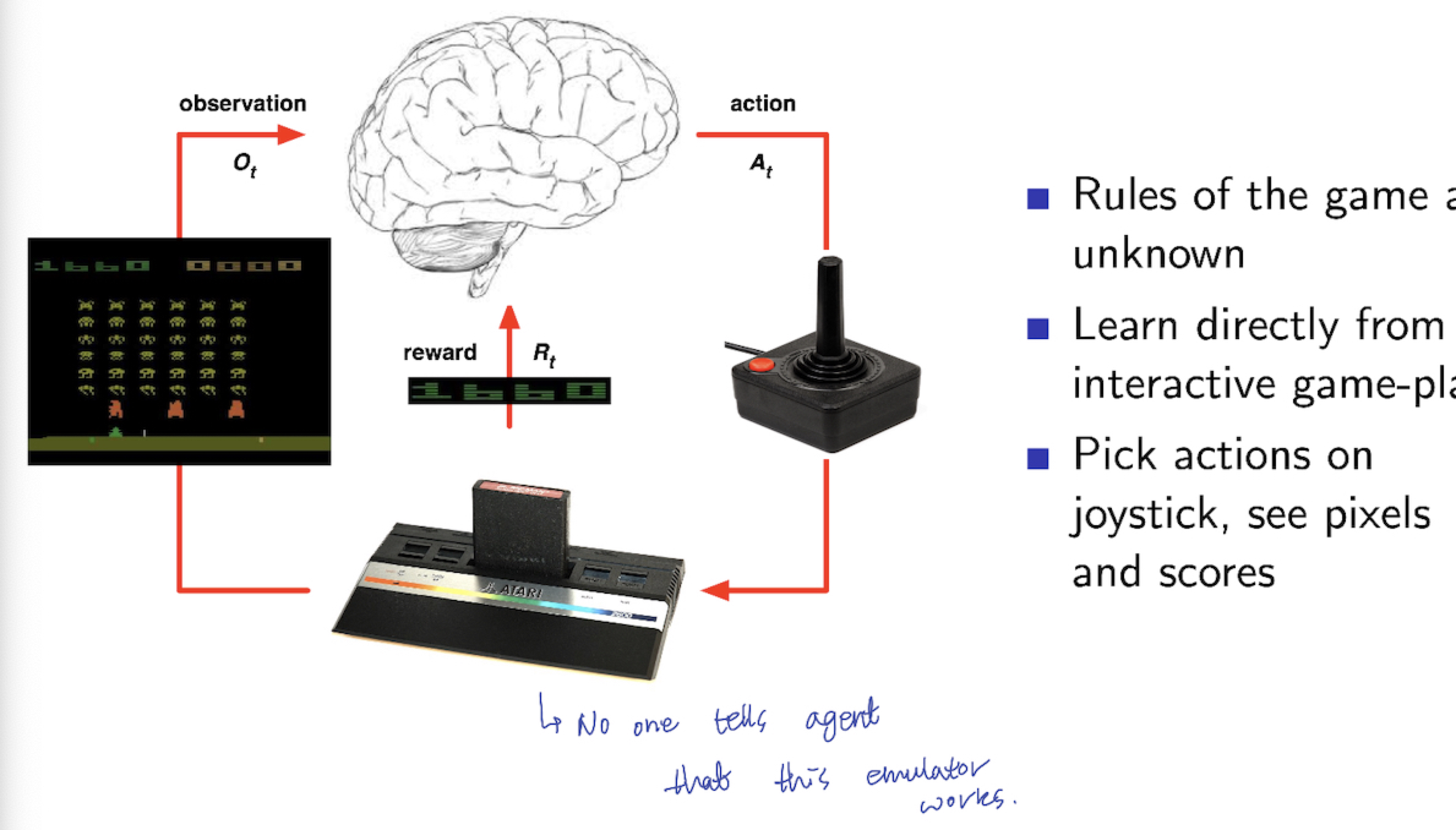
- Environment 에 대해 알지 못함 (Agent 는 아무것도 모른채 그냥 던져짐)
- Agent 가 environment 와 상호작용을 함
- 이를 통해, Agent가 자신의 Policy를 발전시킴
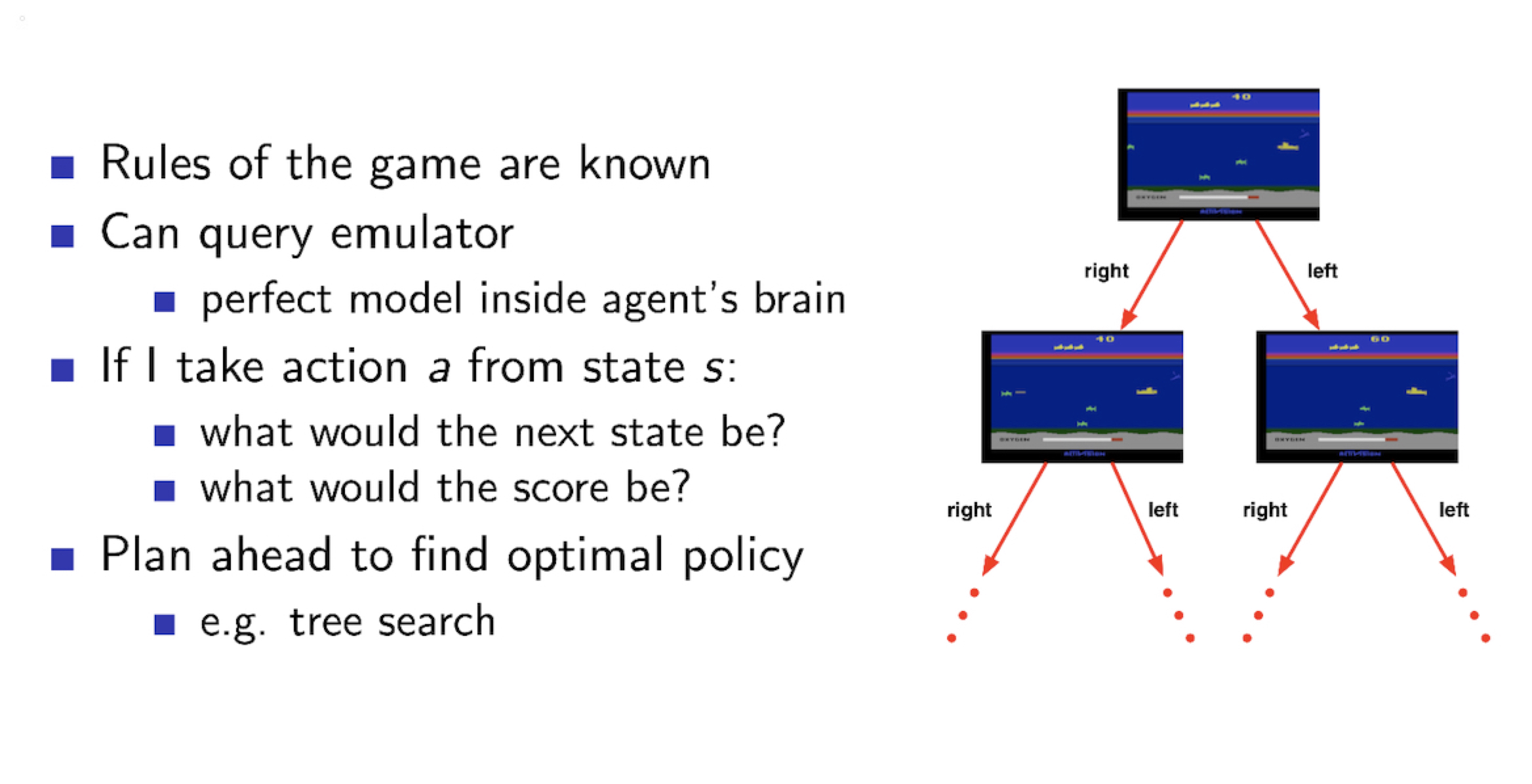
- Planning Problem
- Environment 의 Model 을 알고 있음 ( Agent 가 이 model 을 보고, Environment 에 대한 정보를 가지고 던져짐)
- Agent 는 위 Model 에 대해 computation 을 수행함 (그 어떤 다른 상호작용을 하지 않은채)
- 이를 통해, Agent가 자신의 Policy 를 발전시킴
- aka deliberation (deliberative RL을 검색하니, 같은 hierarchy에 behavior-based architecture(행위 기반 에이전트구조), deliberative agent architecture(숙고형 에이전트 구조), hybrid agent architecture(혼합형 에이전트 구조)가 있으나, deliberation 이 어떤 것인지는 잘 모르겠습니다.) , reasoning, introspection, pondering, thought, search
Atari Game 에서 Reinforcement Learning Problem 으로 바라볼 때,
Atari Game 에서 Planning Problem 으로 바라볼 때,
RL Problem 은 Agent의 Policy dependency 가 높다
→ Model 을 의식하지 않고, Agent를 발전시키는 방향
Planning Problem 은 Model dependency 가 높다
→ Model을 발전시키는 방향
결국 여기서, 얻을 수 있는 것은 같은 문제라 할지라도 우리가 문제정의를 어떻게 하느냐에 따라 Reinforcement Learning 연장을 사용할 때도 다양하게 해석되고, 다양한 문제 해결방식이 있는 것 같습니다.
4.2 Exploration & Exploitation
- 결국, RL 은 trial-and-error learning 입니다.
- The agent 는 environment 에 대한 경험을 통해, Good Policy 를 찾고 발전시켜야합니다.
- 이 때의 제약 조건은 너무 오래 걸리지 않는 시간과 reward step이겠습니다.
- Exploration : finds more information about the environment
- Environment 에 관해 아무것도 알지 못하므로, environment 를 파악하기 위한 정보를 수집합니다.
- Exploitation : exploits known information to maximise reward
- 이미 알고 있는 정보 (Environment 에 관한 정보)를 바탕으로 reward를 최대화합니다.
아래 사진은 각 문제에 대해 Exploitation 관점과 Exploration 관점으로 살펴보았을 때의 그 문제 해결 방법이 달라지는 예시입니다.

4.3 Prediction and Control
- Prediction : Evaluate the future
- Given a policy
- Control : Optimise the future
- Find the best policy
- Agent 를 비롯한 RL system은 결국 Prediction 에서 Control 방향으로 넘어가는 개발단계를 취할 수 있습니다.
[Study] Reinforcement Learning Basic