SPARK BASIC 1
Apache Spark Basic 1
- SPARK 를 공부하면서 실습 과정을 정리해서 남깁니다.
- 실습환경
- CentOS
- Spark 2.4.3
- Hadoop 2.7
1. Spark-shell
1-1. Introduction
shell의 spark home directory 에서 다음 명령어를 통해 spark shell 을 진입할 수 있습니다.
$ cd /spark_home_directory/
$ ./bin/spark-shell
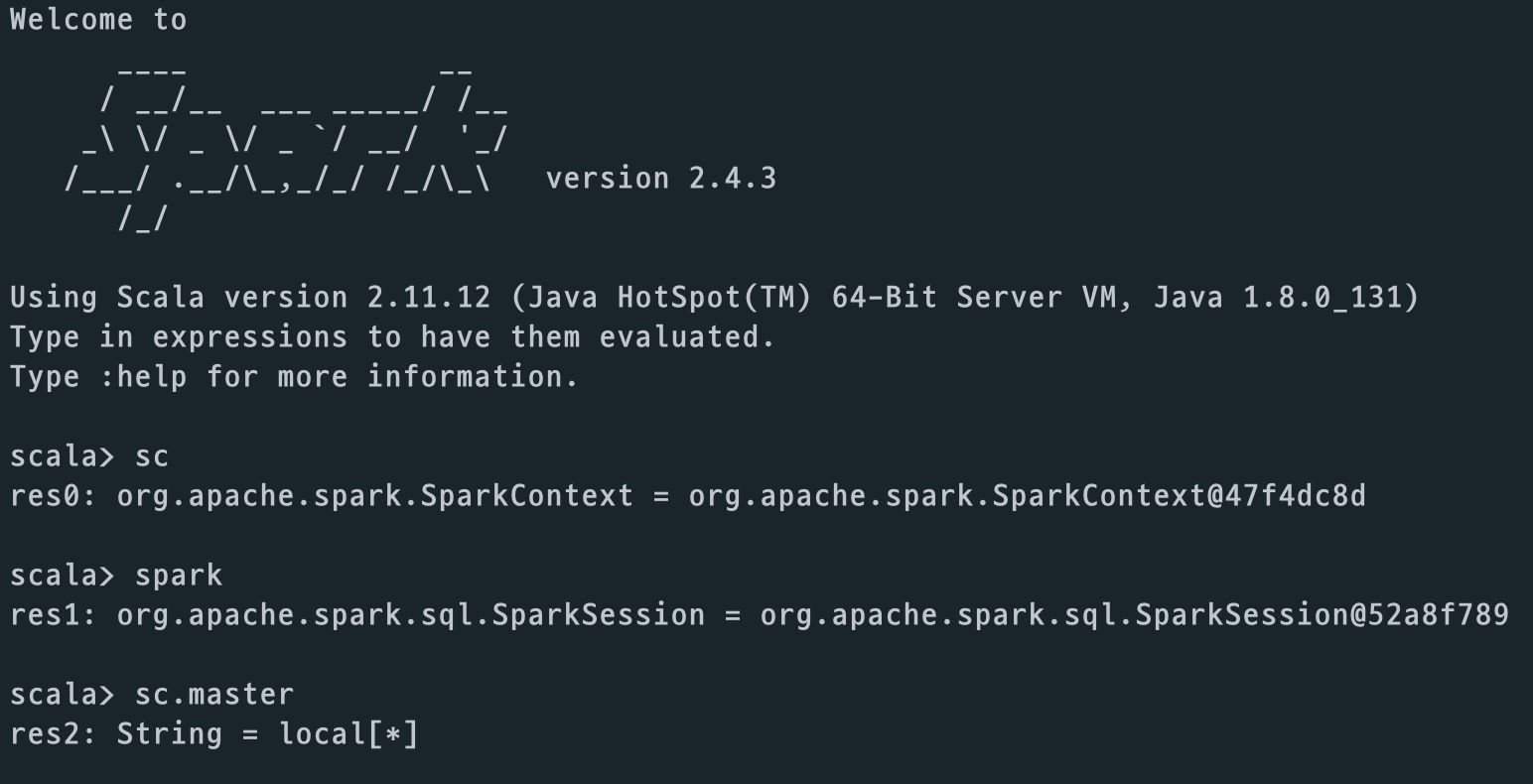
- sc : spark context
- spark : spark session
spark context 와 spark session 의 경우, spark shell에 띄우면서 내부적으로 선언된 변수명이다.
$ jps
// jps 명령어를 통해 현재 돌고 있는 spark process 를 확인할 수 있다.
// spark processor 가 jvm 을 바탕으로 돌기 때문에, jvm 프로세스가 도는 것을 확인하므로써
// 확인 할 수 있는 것이다.
http://localhost:4040, 즉 해당 서버의 ip:4040 포트를 통해서 드라이버에서 제공되는 웹 UI 를 확인할 수 있다. 이 웹 UI 를 통해 현재 작동하는 프로세서와 클러스터들을 관리 할 수 있다.
1-2. RDD
spark는 data를 처리할 때, RDD 와 Spark SQL 을 통해서 data object 를 생성하고 이를 바탕으로 다양한 pipeline 으로 동작 할 수 있다. RDD 를 처음 접해보는 실습.
//scala shell
val data = 1 to 10000
val distData = sc.parallelize(data)
distData.filter(_ < 10).collect()
data가 RDD- sc.parallelize의 return 형 역시 parallelize 된 RDD, 즉 distData 도 RDD
- 마지막 command line 은 10보다 작은 data 에 대해 filtering 하고 각 executor 에서 실행된 자료를 collect()
- spark 의 특징은 .collect() 와 같은 action api 가 실행될 때 모든 것이 실행되는 **Lazy Evaluation (RDD)**으로 동작한다.
드라이버 웹 UI 를 통해 이를 확인 할 수 있다. 이전 command line 에서는 아무 동작도 일어나지 않다가 collect() action api 수행을 통해 실제로 command들이 수행되는 것을 확인 할 수 있다. local 에서 default 로 동작하기 때문에 2개의 partition 으로 동작하며, 어떤 shuffling 도 일어나지 않았기 때문에 1개의 stage 임을 확인 할 수 있다.

// scala shell
// sc.textFile 을 통해 textfile, md 파일등을 읽어드릴 수 있다.
val data = sc.textFile("file_name")
// rdd 의 .map api 를 통해서 rdd 의 element 마다
val distData = data.map(r => r + "_experiment!!")
// 앞선 map 이 수행되고, 각 element(data) 갯수를 세개 된다.
distData.count
여기서는 .count 가 action api 이므로, .count 가 수행될 때, 앞선 command 들이 수행되게 된다.
sc.textFile() 의 경우 ‘\n’, newline 을 기준으로 element 를 RDD 에 담게 된다.
RDD.toDebugString 를 통해 해당 RDD 의 Lineage 를 확인 할 수 있다.
- 가장 왼쪽에 있는 | 를 통해 stage 정보 역시 확인 할 수 있다. shuffle 이 일어나게 되면, stage가 바뀌므로, 서로 다른 stage 에 있는 command 의 경우, 다른 indent에 있게 된다.

RDD.getNumPartitions 를 통해 해당 RDD의 Partition 갯수 (=Task 의 갯수), 즉 병렬화 수준을 확인 할 수 있다.

Shuffle!!
suffle 이 일어나는 경우는 api 마다 다양할 수 있다. 가장 기본적으로, 우리가 default partition 갯수를 변경하므로써 shuffle 이 일어나는 것을 확인 할 수 있다.
val data = sc.textFile("file_name")
data.getNumPartitions
// Partition 의 숫자를 확인해보면, default 이므로 2 인 것을 확인 할 수 있다.
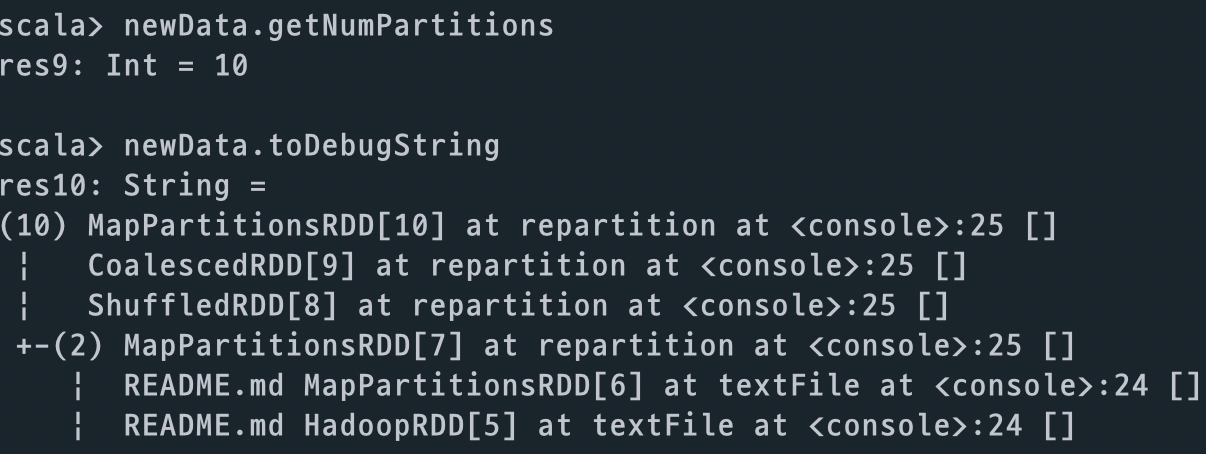
val newData = data.repartition(10)
newData.getNumPartitions
// Partition 갯수가 10로 변경된 것을 확인 할 수 있다.
newData.toDebugString
// newData 의 Lineage 를 확인하면, repartition 이 일어나면서 shuffle 이 되고,
// shuffle 로 인해 stage 가 2개가 되는 것을 확인 할 수 있다.(indentation)
newData.count
// action api 를 수행하여 앞선 command 를 모두 수행
위 command line 에 대한 DAG 를 웹 UI 를 통해 확인하면, 다음과 같이 stage 가 repartition을 기점으로 나누어 지는 것을 확인 할 수 있다.
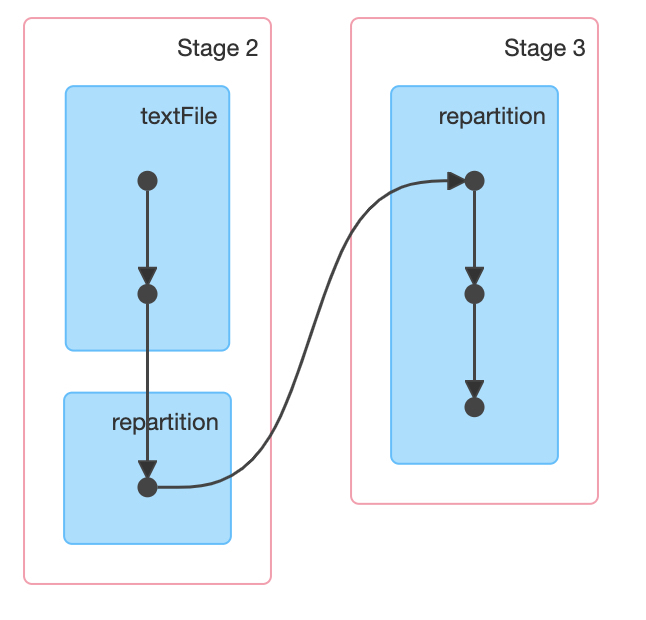
총 Partition의 갯수 (Task의 갯수)를 확인해 보면, default 로 수행된 partition 2 개와, 우리가 설정해준 Partition 의 갯수인 10개를 합하여 12개인 것을 확인 할 수 있다.

여기서 한 스텝을 더 들어가보면, spark 만의 특이한 특징을 확인 할 수 있다.
// 위 코드에 이어서, newData 에 대해
// newData RDD를 collect 해서 cli에 찍는 command 를 수행해보자.
newData.collect.foreach(println)
collect api 와 RDD의 element를 print 를 하는 action api 를 수행할 때, 지금까지 공부한 것으로 생각해 보면, text를 읽어서, 2개의 Partition 을 나누고, 다시 10개의 Partition 을 나누는 작업으로 이전의 12 개의 Task 와 다를게 없을 것 같은 느낌이다. 하지만 UI 를 통해 확인해보면, 10개의 Partition 으로 2개가 skipped 되었다고 확인할 수 있다. DAG 에서도, skipped 된 stage에 대해서 회색으로 확인된다.


이는 spark 에서 이 커맨드라인을 수행할 때, process 간 통신이 file 을 기반으로한 통신을 했기 때문이다. 제일 처음 newData 에 대해서 수행 될 때, 첫 stage 에서 shuffle 이 수행 될 때, 해당 파일을 각 executor 에서 shuffle write 을 하고 저장해두었다가, 두번째 stage 에서 shuffle 이 수행 될때, shuffle read 를 하는 방식으로 file을 기반으로 processor 가 통신하게 된다.

따라서, spark 가 같은 command line 을 수행하게 되면 미리 shuffle write 된 file 을 읽기만 함으로써 앞선 stage 의 동일한 반복 작업을 수행하지 않게 되는 것이다. UI 를 확인 해보아도, shuffle read 만 수행 되었다.

SaveFile!!!
RDD.saveAsTextFile("directory_name") api 를 활용하여, 어떤 처리가 끝난 RDD 를 저장할 수 있다. 이 때 주의 할 점은 parameter 에 들어 가는 것이 directory_name 이라는 것이다. 또한 partition 별로 파일이 저장된다. (e.g. 10개의 partition 이라면, 10개의 file이 저장된다.)
Cache!!!
spark가 자랑하는 가장 큰 특징은, data(RDD) 를 memory에 cache 함으로써 처리의 속도가 매우 빠르다는 점이다. RDD.cache api 를 통해 memory 에 캐시할 수 있다.
// distData RDD 에 이름을 부여
distData.name = "myData"
// cache!
distData.cache
// action : 5 개의 data 를 가져옴
distData.take(5)
// action : collect
distData.collect
distData.take(5) 까지 한 결과를 UI 에서 cache 를 살펴보면, 다음과 같다.

우리가 설정 한 것 처럼, RDD 의 이름이 myData 로 들어간것을 확인 할 수 있고 cache 역시 확인 할 수 있다. 하지만, Cached 된 비율을 확인하면 전체 RDD 에서 50% 만 된 것을 확인 할 수 있다. 반면에, distData.collect action 을 취하게 되면, Fraction Cached 가 100% 가 된 것을 확인 할 수 있다.

이는 우리의 action 에 따라 cache 할 용량이 달라 질 수 있기 때문이다. spark 입장에서 take(5) api 는 전체 RDD 중 5개의 element data 만 가져오면되고, 이 때 2개의 Partition 중 하나의 Partition 만 cache 해도 충분하기 때문에 Fraction Cached가 50%라고 나오는 것이다. 반면 collect api 는 collect 자체가 각 executor 에 있는 data 를 driver 로 모두 가져오는 것이므로 100% cache 하게 된다.
Cache 에서 중요한 것은, 각 executor 의 cache 를 위한 가용 메모리 공간이 해당 Partition의 용량보다 작을 경우, 저장 할 수 있는 용량만큼 저장되는 것이 아니라, 해당 Partition 은 아예 저장이 안되게 된다. 이 점은 Cache를 할 때, Partition 의 용량과 해당 Executor 의 가용 메모리 공간을 미리 파악하여, 설계해야 한다.
Word Count 예제!!!
우리가 데이터 분석을 할 때, 가장 basic 한 방법은 해당 데이터의 갯수를 세어 보는 것이다. 본 예제에서는 텍스트 파일을 읽어, 띄어쓰기를 바탕으로 word token을 나누고, 이를 세어보자.
WordCount 예제는 매우 basic 한 코드이므로, 어떤 로직으로 돌아가는지 완벽한 이해와 코드작성이 필수라고 생각한다.
val originalDataRDD = sc.textFile("text-file")
val wordcountRDD = originalDataRDD.flatMap(line => line.split(" "))
.map(word => (word, 1)).reduceByKey(_ + _)
wordcountRDD.collect.foreach(println)
- originalDataRDD 에서 text-file을 읽고,
- line 마다 띄어쓰기를 기준으로 split 하고 이를 .flatMap 을 통해, flatten 하게 됩니다.
- 그리고 .map 을 통해 (word, 1) tuple 형태로 mapping 합니다.
- .reduceByKey 를 통해 같은 word 에 대해 그 counting 갯수를 더하게 된 것을 RDD 로 return 하게 됩니다.
SPARK BASIC 1