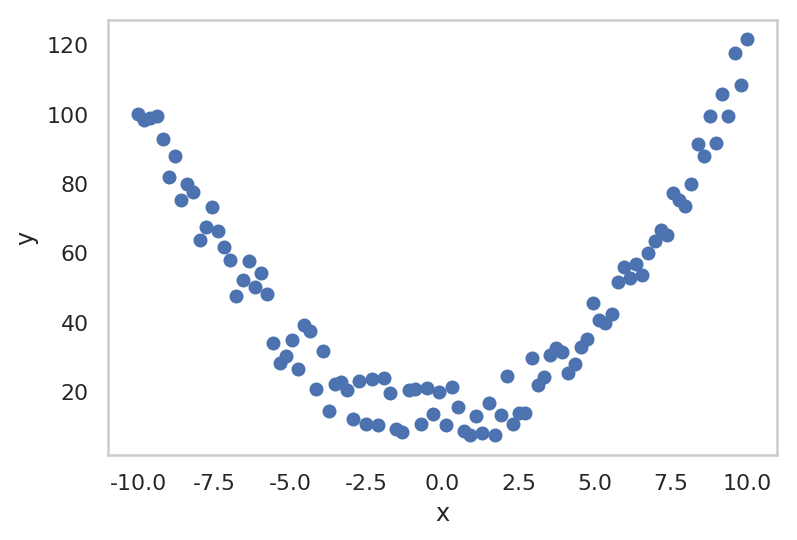
for epoch inrange(1, epochs + 1): hypothesis = model(x_train) # define loss loss = F.mse_loss(hypothesis, y_train) # Backprop & update parameters optimizer.zero_grad() loss.backward() optimizer.step() if epoch % 1500 == 0: print("epoch: {} -- loss {}".format(epoch, loss.data))
epoch: 1500 -- loss 0.22306101024150848
epoch: 3000 -- loss 0.11560291796922684
epoch: 4500 -- loss 0.09848319739103317
epoch: 6000 -- loss 0.08879078179597855
epoch: 7500 -- loss 0.08104882389307022
epoch: 9000 -- loss 0.07452096790075302
epoch: 10500 -- loss 0.06889640539884567
epoch: 12000 -- loss 0.06398065388202667
epoch: 13500 -- loss 0.05964164435863495
epoch: 15000 -- loss 0.055785566568374634
Adam 은 adaptive 하게 learning rate 를 조정해 주는 algorithm 입니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
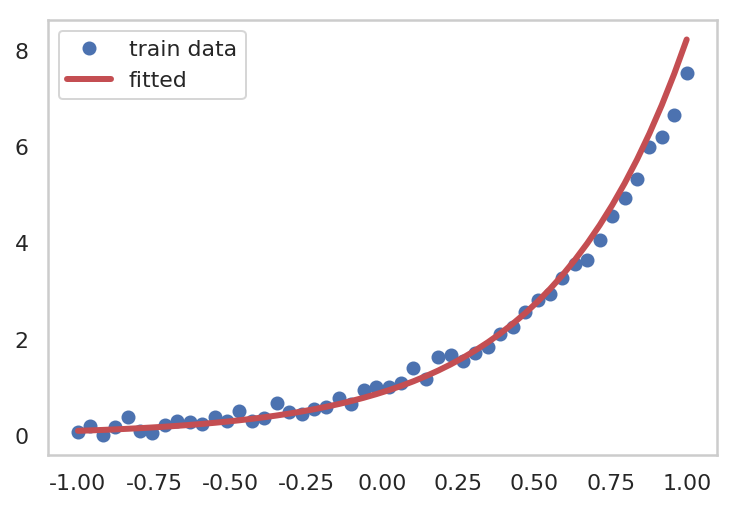
model = ExpModel()
optimizer = optim.Adam(model.parameters())
epochs = 15000
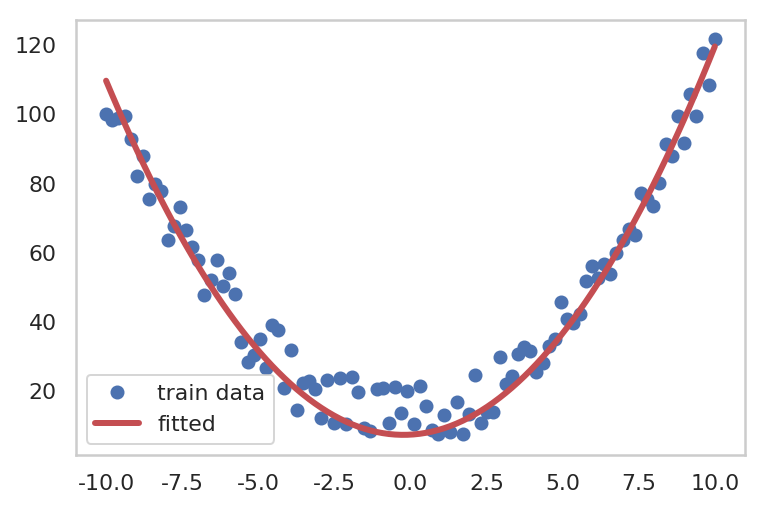
for epoch inrange(1, epochs + 1): hypothesis = model(x_train) loss = F.mse_loss(hypothesis, y_train) optimizer.zero_grad() loss.backward() optimizer.step() if epoch % 1000 == 0: print("epoch: {} -- loss {}".format(epoch, loss.data))
epoch: 1000 -- loss 1.4807509183883667
epoch: 2000 -- loss 0.6568859815597534
epoch: 3000 -- loss 0.2930431365966797
epoch: 4000 -- loss 0.1839657723903656
epoch: 5000 -- loss 0.1683545857667923
epoch: 6000 -- loss 0.16775406897068024
epoch: 7000 -- loss 0.16775156557559967
epoch: 8000 -- loss 0.16775153577327728
epoch: 9000 -- loss 0.16775155067443848
epoch: 10000 -- loss 0.16775155067443848
epoch: 11000 -- loss 0.16775155067443848
epoch: 12000 -- loss 0.16775155067443848
epoch: 13000 -- loss 0.16775153577327728
epoch: 14000 -- loss 0.1677515208721161
epoch: 15000 -- loss 0.1677515208721161
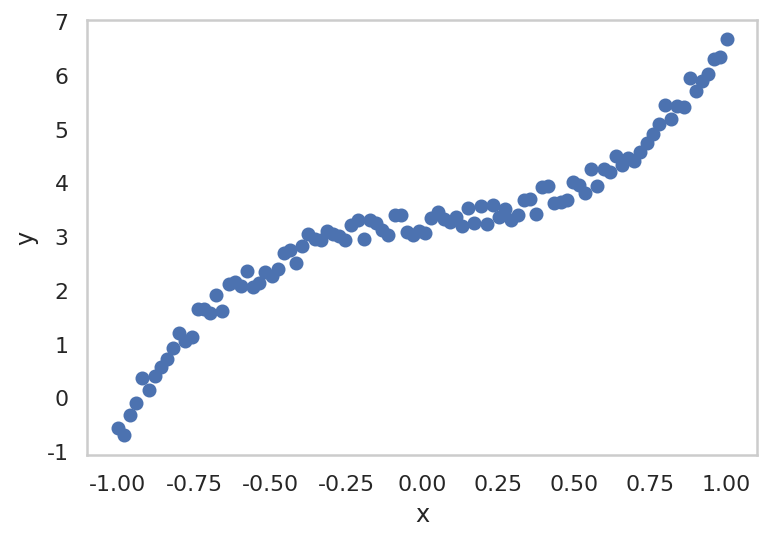
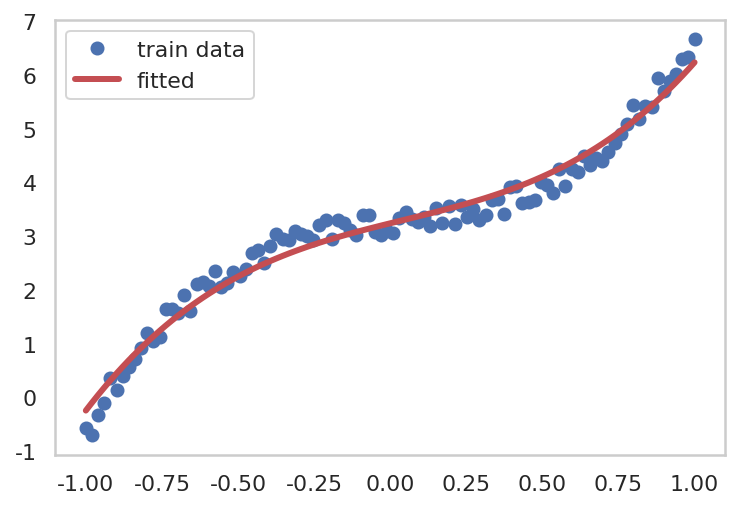
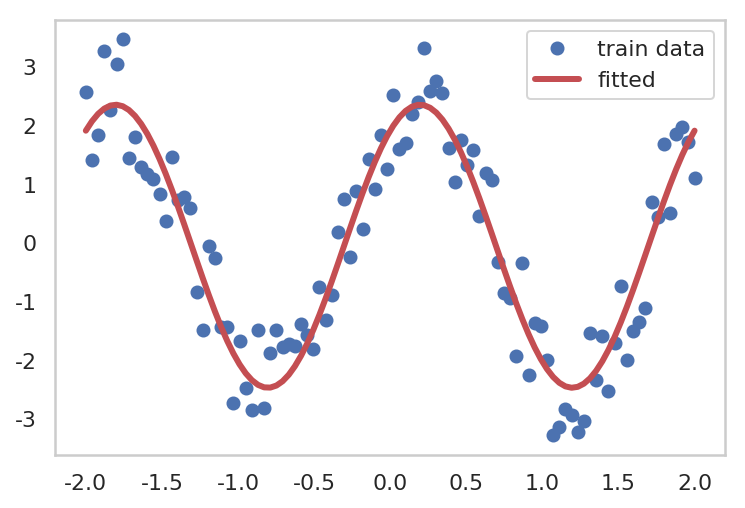
for epoch inrange(1, epochs + 1): hypothesis = model(x_train) loss = F.mse_loss(hypothesis, y_train) optimizer.zero_grad() loss.backward() optimizer.step() if epoch % 1000 == 0: print("epoch: {} -- loss {}".format(epoch, loss.data))
epoch: 1000 -- loss 1.1333037614822388
epoch: 2000 -- loss 0.45972707867622375
epoch: 3000 -- loss 0.36056602001190186
epoch: 4000 -- loss 0.3566252291202545
epoch: 5000 -- loss 0.3566077649593353
epoch: 6000 -- loss 0.3566077947616577
epoch: 7000 -- loss 0.3566077649593353
epoch: 8000 -- loss 0.3566077947616577
epoch: 9000 -- loss 0.3566077947616577
epoch: 10000 -- loss 0.3566077649593353