DeepSeekMoE 요약
논문 DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models를 읽고 주요 contribution 내용과 개인적으로 꼭 기억할 내용을 요약하여 정리해본다.
Abstract
문제 정의
- 최근 LLM이 발전하면서 더 많은 파라미터를 활용할 수록 성능이 향상 → but, 그에따른 연산 비용 급격히 증가 → 이를 해결하기 위해 Mixture-of-Experts (MoE) 아키텍처 등장
- MoE: 여러 개의 전문가 모델 (Experts) 을 두고, 입력 데이터에 따라 일부 전문가만 활성화하여 계산하는 방식
- 이 방식은 전체 모델 크기는 증가할 수는 있으나,
- 한 번의 inference에서 사용되는 연산량을 줄일 수 있다.
- 기존의 대표적인 MoE 아키텍처 GShard(구글) 방식은 다음과 같은 문제점이 있다.
- Spicialization 문제 : GShard에서는 N개의 전문가(Experts) 중 K개를 선택 (Top-K Routing)하여 활성화하지만, 특정 Expert 들이 중복된 지식을 학습하는 문제가 있을 수 있고, 각각의 Expert가 전문화(specialization)되지 않는 문제가 발생할 수 있음
- 즉, 모델이 각 전문가를 “고유한, 특별한 역할”을 가진 전문가로 만들지 못하고 일부 전문가가 과하게 중복된 역할을 수행하는 비효율성이 있다.
Key Idea
- 본 논문에서는 DeepSeekMoE라는 새로운 MoE 구조를 제안
- 목표는 각 Expert를 Specialization을 극대화하기 위함
- 두 가지 핵심 전략 소개
- Expert Segmenting(전문가 세분화) 및 Activation 방식 개선
- 기존 GShard는 N개의 전문가 중 K 개만 선택하는 방식이었으나,
- DeepSeekMoE에서는 각 전문가를 더 작은 단위로 세분화 ($mN$개 전문가)하여, $mK$개의 전문가를 Activate 하는 방식을 사용
- 이를 통해 더 다양한 조합의 Expert들을 활성화할 수 있으며, Expert간의 Knowledge 중복을 줄이고, 유연한 조합이 가능
- Shared Experts (공유 전문가(?)) 도입
- 일부 Expert ($K_{s}$)를 Shared Experts로 따로 분리
- 이 Shared Expert는 일반 상식, 지식 (Common Knowledge) 학습
- 나머지 Expert들은 특정한 역할을 수행하는 것으로 특화
- 이렇게 함으로써 각 전문가가 중복 없이 고유한 정보를 학습할 수 있으며, 동시에 일반 상식은 Shared Expert가 담당하므로 불필요한 중복 연산을 줄일 수 있다.
Experiment
- DeepSeekMoE의 효과성을 검증하기 위해, 기존 모델들과 성능 비교
- 2B 크기
- DeepSeekMoE 2B와 기존 Gshard 2.9B와 비교하여 1.5배 적은 Expert parameter와 연산량을 사용하면서도 동일한 성능을 보임
- 16B 크기
- DeepSeekMoE 16B는 기존의 llama2 7B와 비슷한 성능, but 40% 정도의 연산량만 사용
- 더 적은 연산량으로도 동일한 성능을 유지할 수 있음을 보임
- 145B 크기
- DeepSeekMoE 145B는 Gshard 보다 우수한 성능, DeepSeek 67B 모델과 비교해서 비슷한 성능, but 연산량은 DeepSeek 67Bdml 28.5%(혹은 최소 18.2%)만 사용
- 마찬가지로 기존 방식 대비 연산량을 대폭 줄이면서도 높은 성능을 유지할 수 있음을 보임
Preliminaries: 트랜스포머의 MoE
트랜스포머 기반의 언어 모델은 기본적으로 $L$개의 standard transformer 블록을 쌓아서 구성된다. 각 블록은 다음과 같이 표현될 수 있다.
$$
u_{1:T}^{l} = Self-Att(h_{1:T}^{l-1}) + h_{1:T}^{l-1}
$$
$$
h_{t}^{l} = FFN(u_{t}^{l})+u_{t’}^{l}
$$위 식에서 $T$는 시퀀스 길이
$Slef-Att$ : 셀프 어텐션 모듈
$FFN(\cdot)$ : feed forward network
$u_{1:T}^{l} \in R^{T \times d}$ 는 $l$ 번째 어텐션 모듈을 거친 후의 모든 토큰의 hidden state
$h_{t}^{l} \in R^{d}$ 는 $l$ 번째 트랜스포머 블록을 통과한 후 $l$ 번째 토큰의 출력 hidden state
수식에서 Layer Normalization은 생략
MoE 언어 모델을 구성하는 일반적인 방법은 트랜스포머 내에서 특정 간격마다 $FFN$ 을 MoE 레이어로 대체하는 것
MoE 레이어는 여러 Experts로 구성되며, 각 Expert는 구조적으로 Feed Forward Network와 동일한 형태를 갖는다.
- 이후 각 토큰은 하나의 Expert에 할당 될 수도 있고,
- 두 개의 Expert에 할당될 수도 있다.
만약 $l$번째 FFN 이 MoE레이어로 대체된다면, 해당 레이어에서의 output hidden state $h_{t}^{l}$ 은 다음과 같으 계산됨
$$
h_{t}^{l} = \Sigma_{i=1}^{N}(g_{i, t}FFN_{i}(u_{t}^{l})) + u_{t}^{l}
$$
이 식을 추가적으로 설명하면 각 Expert $FFN_{i}$ 가 입력 $u_{t}^{l}$을 입력 받아 가중치 g와 곱해서 더한다. 입력 ut와 더하는 것은 residual connection (잔차 연결)로 볼 수 있음
$$
g_{i,t} = s_{i, t} \quad or \quad 0 \quad where \quad s_{i, t} \in Topk(<!–swig0–>e_{i}^{l})
$$
각 Expert에 대한 가중치 $s_{i, t}$ 값은 Softmax로 계산됨.
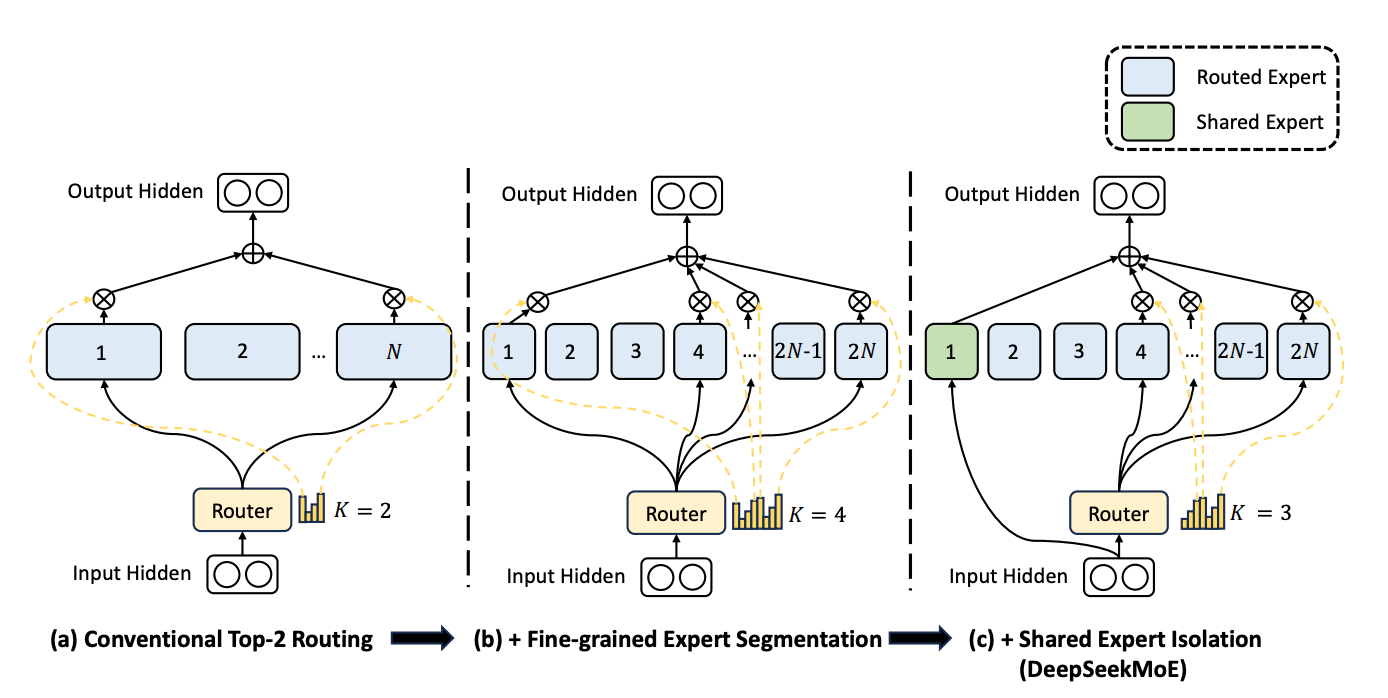
그림 (a)는 Top-2 Routing 하는 moe 레이어
그림 (b)는 Fine-grained expert segmentation 전략
그림 (c)는 shared expert isolation 전략, DeepSeekMoE 아키텍처
DeepSeekMoE 아키텍처
- DeepSeekMoE는 2가지를 제시
- Fine-grained Expert Segmentation (세분화된 expert 분할)
- Shared Expert Isolation (공유 전문가 분리)
- 이 두가지 전략 모두 각각의 Expert의 전문성을 더욱 강화하는 것을 목표로 함
Fine-Grained Expert Segmentation
- 기존 MoE 구조에서 전문가의 수가 제한적이면, 각 전문가에게 할당된 토큰들이 다양한 종류의 지식(Knowledge)을 포함할 가능성이 높아짐
- 결과적으로, 하나의 전문가가 너무 많은 종류의 지식을 학습해야 하며, 이러한 지식들은 동시에 효과적으로 활용되기가 어려움
- 이를 해결하기 위해 각 토큰이 더 많은 전문가에게 라우팅될 수 있다면, 각 전문가가 더 세분화된 특정 지식만을 학습할 수 있도록 조정할 수 있음
- 이렇게 하면 전문가가 더욱 집중된(특화된) 지식을 학습할 수 있으며, 결과적으로 각 전문가 간의 역할이 더욱 명확하게 분배
구체적으로, 기존 MoE 아키텍처(그림 (a))에서 각 전문가의 FFN을 𝑚개의 더 작은 전문가로 분할한다.
이때, 각 전문가의 FFN의 중간(hidden) 차원을 원래 크기의 $\frac{1}{m}$로 줄인다. 각 전문가가 작아진 만큼, 활성화되는 전문가의 수를 $𝑚$배 증가시켜, 전체 연산 비용을 동일하게 유지할 수 있도록 조정합니다 (그림 (b)).
Shared Expert Isolation
- 기존의 라우팅 전략에서는, 서로 다른 전문가에게 할당된 토큰들이 공통적인 지식이나 정보를 필요로 할 수 있음. 그 결과, 여러 전문가들이 동일한 지식을 학습하게 되어 파라미터 중복이 발생함.
- 그러나, 특정 전문가를 공유 전문가로 지정하여 여러 문맥에서 필요한 공통 지식을 담당하도록 하면,다른 전문가들의 중복 학습이 줄어들어 모델이 더욱 효율적인 구조를 가질 수 있음.
- 이는 전문가 specialization를 강화하고, 모델이 적은 파라미터로도 효과적인 성능을 내도록 만듦.
이를 위해, 세분화된 전문가 분할(Fine-Grained Expert Segmentation) 전략과 함께 $𝐾ₛ$개의 전문가를 공유 전문가로 따로 분리함. 이때,
- 라우터 모듈과 관계없이 모든 토큰은 항상 이 공유 전문가들에게 배정됨.
- 연산 비용을 일정하게 유지하기 위해, 다른 전문가들에게 라우팅되는 활성 전문가 수를 𝐾ₛ만큼 감소시킴.
- 그림 (c) 참고
DeepSeekMoE 요약