[논문리뷰] Real-time Attention Based Look-alike Model for Recommender System (Part 1)
본 글에서는 Real-time Attention Based Look-alike Model for Recommender System 논문의 핵심을 살펴보고, 위 논문의 각 파트를 구현하면서 마주한 문제와 고민을 공유해보고자 한다. Part 1, 2로 나누어 User representation learning 파트와 Online Processing 파트를 나누어 살펴보자.
광고를 송출 하는데 있어, 요즘 내가 풀고 있는 문제는 “오디언스의 확보”이다. 광고주마다 특정 KPI 를 달성하는데 필요한 오디언스는 정해져있다고 전제할 때, 광고 시스템은 전체 오디언스 풀에서 특정 KPI를 달성하는데 유리한 오디언스를 찾아내 타겟팅, 리타겟팅을 잘 해내야 한다. “오디언스 확보”를 위해서 다양한 아이디어에 근간해 개발을 하고 있고, 우리 광고 시스템에 실험을 하고 있다. 그 중 RecSys분야에서 재미있게 읽은 Attention based Look-alike Model 논문을 리뷰해 본다. Look-alike Model 은 특정 캠페인에서 효율(간단하게는 CTR, CVR 등)이 좋았던 N명의 오디언스의 특징을 찾고, 전체 오디언스 풀에서 N명과 유사한 M을 찾는 것이다.
Key Features
본 논문의 핵심은 3가지로 구분된다. 1. User representation을 학습하는 offline train model 2. Seeds representation 을 학습하는 비동기 online processing 3. user와 seed간의 similarity를 계산하고, 점수를 매겨 서빙하는 Online Serving
본 논문을 직접 구현하는데 있어 가장 중요한 것은 1, 2번의 모델링 방법이다. 3의 경우, 각 회사나 시스템마다 적용할 수 있는 방법은 다양하게 있을 것이다. 본 글에서는 1번에 집중하여 핵심을 파악해보자. 다음글에서 2번 모델에 알아보자.
1. User Representation Learning
유저 profile 데이터는 매우 다양하게 있을 것이다. 기본적인 메타데이터부터 특정 광고 캠페인에서의 클릭수, 랜딩 페이지, 랜딩 페이지에서의 활동 등. user 를 표현 할 수 있는 profile feature data 는 잘 정제 되어 있다는 전제하에 본 논문이 제시하는 user representation learning 모델을 살펴보자.
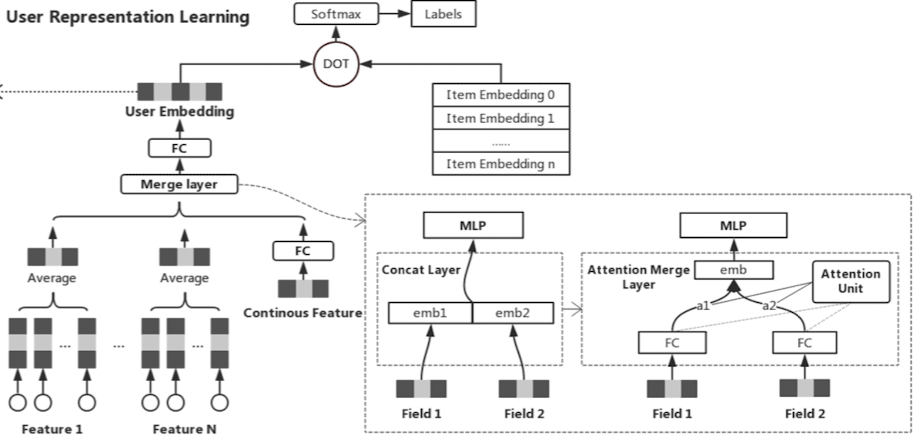
그림 : User representation learning Model Architecture
Sampling
먼저, 본 논문은 user representation embedding 을 학습시키기 위해 multi-class classification 문제를 만들었다. 유저마다 클릭하는 아이템의 카테고리를 부여하고, 각 카테고리로 분류하는 문제이다. 이 때 수 많은 카테고리가 존재할 것이고, 유저의 분포와 카테고리 마다의 분포가 학습시키는데 불리하므로, 다음과 같은 negative sampling 을 활용했다.
$$
p(x_{i})= \frac {log(k+2)-log(k+1)}{log(D+1)}
$$
- $x_{i}$ : i번째 아이템
- $k$ : i 번째 아이템의 랭크
- $D$ : 아이템 랭크의 최댓값
- $p(x_{i})$ : i번째 아이템이 뽑힐 확률
본 논문에서는 negative sampling 에서 poitive : negative 의 비율을 1:10으로 설정했다.
모델 구조
본 몬문에서는 위의 multi-class classification 문제를 풀기 위해, 모델 구조는 다음과 같이 간단하다.
- Embedding layer : (user, item)
- (2-1) Concatenation layer : 붙이자! or (2-2) Attention merge layer : 잘 붙이자!
- Multi layer perceptron
- (optimizer) Adam optimizer
마지막 Loss 는 Cross Entropy Loss
$$
L = - \Sigma_{j \in X} y_ilogP(c=i| U, X_{i})
$$
- $X$: 아이템 embedding 집합
- $y_{i}$ : 0 or 1 의 라벨
Attention Merge Layer
본 논문에서는 단순 concatenation layer 을 사용하니, 특정 아이템 필드에서 오버피팅 되는 문제가 있어, 강하고 약한 상관관계를 묘사하기 위해 다음과 같은 attention 유닛을 사용했다.
$$
u=tanh(W_{1}H)
$$
$$
a_{i} = \frac {e^{W_{2}u_{i}^{T}}}{\Sigma_{j}^{n}e^{W_{2}u_{j}^{T}}}
$$
- $h \in \mathbb {R}^m$, $H \in \mathbb {R^{n \times m}}$
- $W_1 \in \mathbb{R}^{k \times n}$, $W_2 \in \mathbb {R}^{k}$
- $u \in \mathbb{R}^n$ : activation 유닛
- $a \in \mathbb{R}^{n}$ : attention weight
- $k$ : attention 유닛 사이즈
위 식을 계산하고, 최종적으로 concatenated layer 를 대신하는 vector 는 다음과 같이 계산된다.
$$
M=aH
$$
2. User Representation Learning 구현에 있어서 마주한 문제들.
2-1. User Profile Data
처음과 끝은 데이터임은 모든 데이터사이언티스트가 가지고 있는 고민이다. 양질의 데이터 웨어하우스를 구성하는것. 본 논문을 구현하고 시스템에 테스트 하는데 있어 가장 오랜 시간이 걸린 것이 입력 데이터 웨어하우스를 구성하는 것이었다. 기존에 사용하고 있는 데이터에서 attention 학습을 위해 시계열적인 학습 데이터를 구성했다. 그리고 여전히 추가되는 새로운 feature에 대해서도 고민하고 있다. 광고 특성상 각 소재 및 매체마다 붙는 IAB 카테고리 뿐만 아니라, 유저의 활동에도 각 카테고리 값을 시계열적으로 담았다. 본 논문의 아이디어를 차용해, 일정 기간 동안 클릭 및 전환하는 IAB 카테고리 내에서의 네거티브 샘플링을 적용했다.
2-2. Attention Merge Layer의 효과
본 논문처럼 나 역시 base model을 단순 concatenated layer 로 잡았다. (torch.concat 만 하면 되니까..) 반면에 논문에서 소개된 구조로 attention layer를 추가한 다음 모델에서는 학습 시키는데 어려움이 있었다. 특정 attention weight 만 업데이트 되는 문제를 발견하게 되었다. attention 목적에 맞는 기능을 하긴 했으나, 특정 attention weight 만 업데이트가 되면서, 일부 item embedding 은 반영되지 못하는 효과가 있었다. 이를 만회하기 위해, 나는 attention merge layer 와 base 모델의 concatenated layer 구조를 z 축으로 붙여 학습시키기도 하였다. 수치상으로는 앞 선 두 구조보다 나은 결과를 보였으나, 해당 구조가 같는 의미와 기능은 조금더 고민해보아야 한다.
[논문리뷰] Real-time Attention Based Look-alike Model for Recommender System (Part 1)
https://emjayahn.github.io/2023/02/26/20230226-paper-RALM-1/