[CS231n]Lecture02-Image Classification Pipeline
Lecture 02: Image Classification Pipeline
- 이 글은, Standford University 의 CS231n 강의를 듣고 스스로 정리 목적을 위해 적은 글입니다.
1. Image Classification 의 기본 TASK

- 위 사진을 보고, → ‘CAT’ 혹은 ‘고양이’ 라고 classification
- 자연스럽게 따라오는 문제는 “Sementic Gap” : 우리가 준 data (pixel 값 [0, 255]) 와 Label 간의 gap
- 또한, 이 과정에서 극복해야 하는 Challenges
- Viewpoint Variation ( 같은 객체에 대해 시점이 이동해도 robust)
- Illumination ( 빛, 밝기, 명암 등에도 robust)
- Deformation ( 다양한 Position, 형태의 변형에도 robust)
- Occlusion ( 다른 물체나 환경에 의해 가려지는 data 에도 robust)
- Background Clutter ( 배경과 비슷하게 보이는 객체에도 robust)
- Intraclass Variation ( 한 종류의 클랫스에도 다양한 색과 모습의 객체가 있을 수 있다.)
2. 기존의 시도와 New Era
- Hard Coded Algorithm 과 여러 규칙 (rule-based로 해석된다) 들을 통해서 Image를 Classify 하는 노력들이 있어왔다. 이들의 문제는, (1) 위에 언급한 문제들이 Robust 하지 않다. (2) 객체가 달라지면, (고양이, 호랑이, 비행기 등) 객체마다 다 다른 규칙을 성립해줘야 한다. 즉 한마디로 요약하자면, Algorithm의 확장성이 없다.
- 이런 문제에 좀더 강한 방법이 지금 우리가 공부하고 있는, Data-Driven Approach
- Image 와 Label pair 의 dataset 을 모은다.
- Machine Learning 알고리즘을 이용해 classifier 를 학습시킨다.
- Classifier 를 new images 에 테스트에 평가한다.
3. First Classifier : Nearest Neighbor
3-1. Nearest Neighbor 의 기본 알고리즘
- train set 에서의 모든 data 와 label 을 기억한다.
- test Image 와 가장 가까운 train Image 의 label로 test image를 predict 한다.
- 이 때 ‘가장 가까운’ 을 계산 할 때**, L1 distance** 와 L2 distance 가 쓰일 수 있다. 이 외에도, 다양한 distance 지표가 쓰일 수 있다.
3-2. Nearest Neighbor Classifier 의 문제
- 이미지 classification 에는 잘 사용되지 않는다.
- train 보다 predict 하는데 훨씬 오래 걸린다.
- train 은 train data set 의 기억만 하면 되지만, predict 할 때는 전체 train data 에 대해 거리를 측정해야하고, sorting 해야하는 문제가 발생한다.
- Time Complexity - train O(1), predict O(N) (N은 train data 수)
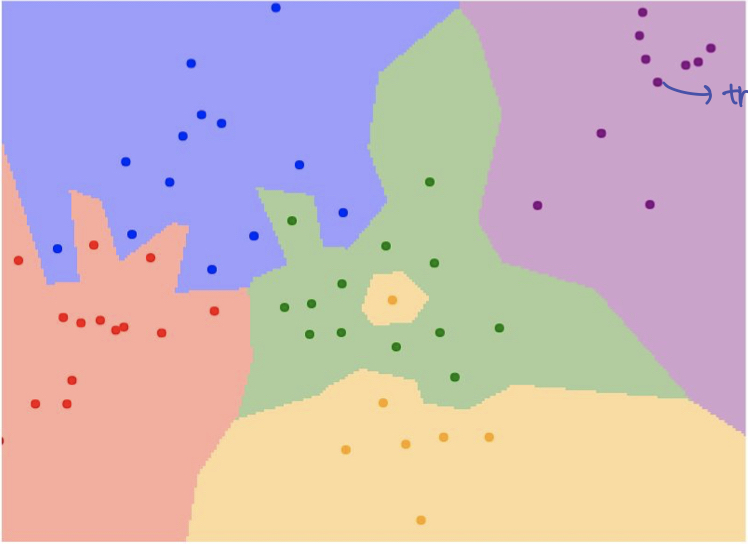
위 그림을 보면, 연두색 공간에 노란색 class 가 포함 되어 있는 것을 볼 수 있다. 이는 generalize 면에서 부족한 모델이라고 볼 수 있다. 같은 알고리즘 이지만, 이를 해결 하는 방법은 K 개의 가까운 neighbor 로 부터 majority voting 을 받은 것으로 classify 를 하는 것이다.
3-3. K-Nearest Neightbors
Single Nearest 만 보는 것이 아니라, K 개의 가까운 point 의 투표를 통해 해당 test data 의 label 을 예측한다.
- 이 때, Voting 하는 방법에는 majority voting ( 다수결 ) 과 weighted voting ( 가중치를 주어 투표: distance 가 가까운 것에 가중치를 준다.)
- 가중치를 주는 방법에는 distance 가 커지면 곱해지는 weight 을 줄이는 방법으로 1 / (1+distance) 등을 weight 을 곱해준다.

3-4. k-Nearest Neighbor on images NEVER USED
- 차원의 저주 문제
- knn 이 잘 동작하기 위해서는 dataset 공간을 조밀하게 커버할 만큼의 충분한 training space 가 필요하다. 하지만, data 의 차원이 늘어날 수록 그 충분한 data 의 수가 exponential 하게 늘어난다.
4. Setting Hyperparameters
Model 최적의 hyperparameter 를 찾기 위해서는 data set 을 구분하여, unseened data 를 사용하여 성능 검증을 하고, model selection 을 해야한다. 이는 단순이 hyperparameter 를 찾는 용도 뿐만 아니라 우리가 세운 가설을 서로 비교 할 때는 data set 을 정확히 구분하고, test set 을 통해 비교하고, 선택해야한다. 그 방법에는 train, validation, test set 으로 dataset 을 나누는 방법과 cross validation 방법이 있다.
- 첫 번째 방법으로는, Validation set 을 통해 hyperparameter(가설)를 검증하고 선택하여, Test set 을 사용하여 Evaluate 과 Reporting 등을 한다. 딥러닝 모델링에서는 이 방법으로 많이 사용한다.

- 두 번째 방법은, data set 의 크기가 크지 않을 때, Train set 안에서 folds 들을 나누어 각 fold 가 돌아가며 validation set 이 되며, 이들의 평균값으로 가설을 비교한다. 이는 딥러닝 모델에서는 적합하지 않은 형태이다. 모델 자체의 연산이 많은데다가, 같은 모델에 대해 많은 validation 이 효율적이지 않기 때문이다. 또한 data가 많지 않은 상태에서 딥러닝 모델을 선택하는 것은 옳지 않다.

5. Second Classifier : Linear Classifier
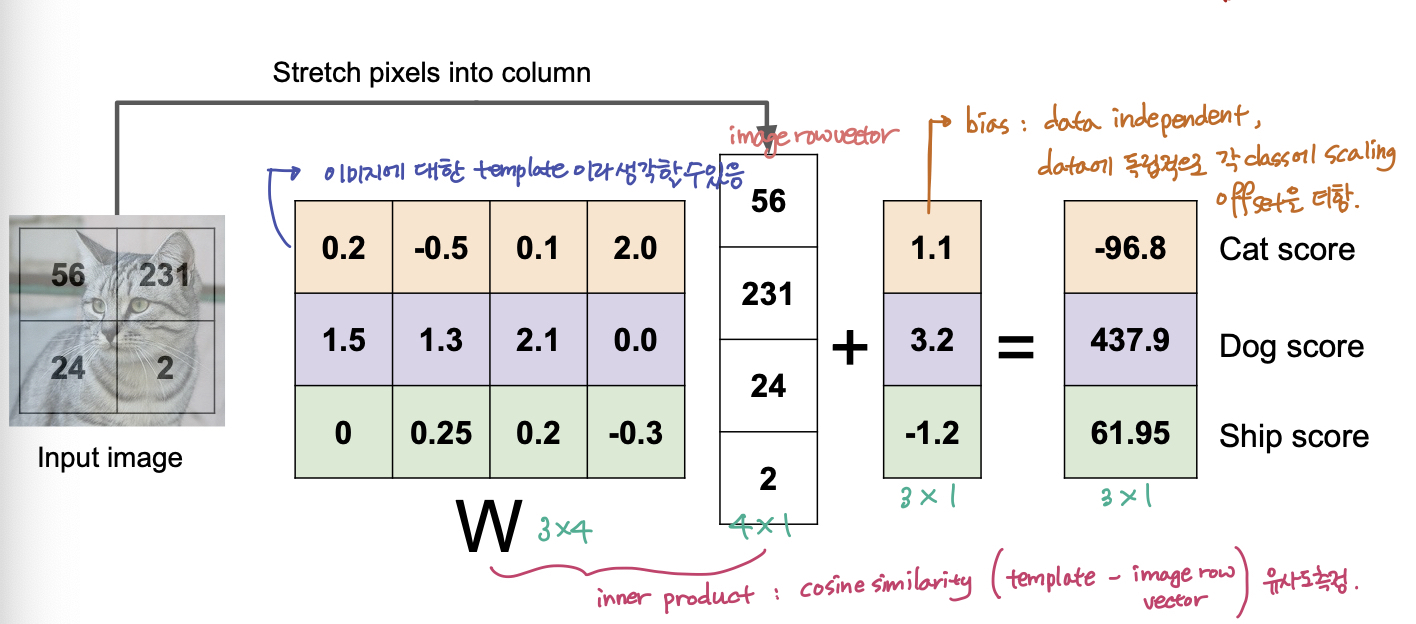
Linear Classifier 는 Neural Network 의 기본 골격이다. (1) image data 와 W (parameters or weights) 을 통해 연산을 해주고, (2) function 을 통과해 Classification 을 해준다.
특히 Linear Classifier 의 경우 아래 와 같이, (1) image data 와 W 를 dot product 를 해주고 (2) linear function f 를 통과한다.
$$f(x, W) = Wx$$
6. Reference
[CS231n]Lecture02-Image Classification Pipeline
https://emjayahn.github.io/2019/05/13/CS231n-Lecture02-Summary/