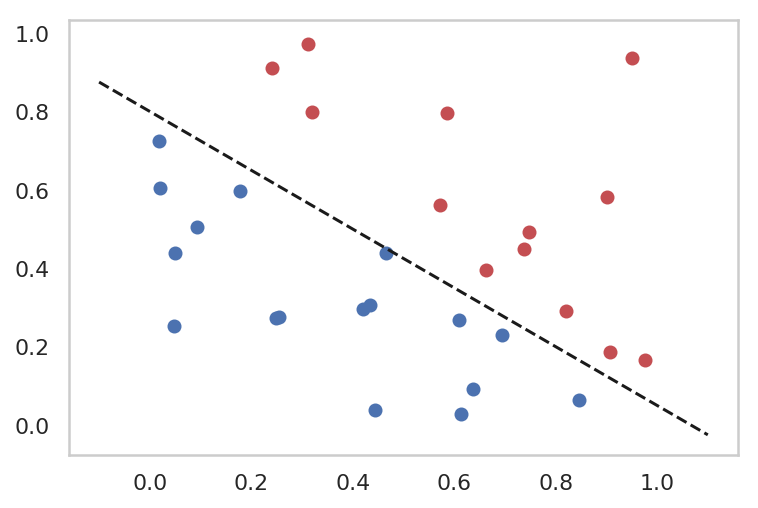
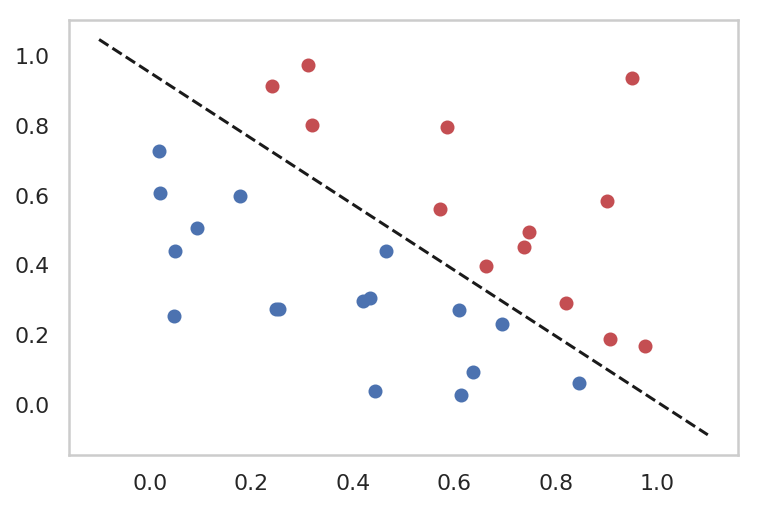
for epoch inrange(1, epochs + 1): # Prediction y_hat = F.sigmoid(torch.matmul(x_train, parameter_W)) # Loss function loss = (-y_train * torch.log(y_hat) - (1 - y_train) * torch.log((1 - y_hat))).sum().mean() # Backprop & update optimizer.zero_grad() loss.backward() optimizer.step() if epoch % 1000 == 0: print("epoch {} -- loss {}".format(epoch, loss.data))
epoch 1000 -- loss 6.368619441986084
epoch 2000 -- loss 4.5249152183532715
epoch 3000 -- loss 3.654862403869629
epoch 4000 -- loss 3.122910261154175
epoch 5000 -- loss 2.7545464038848877
epoch 6000 -- loss 2.4800000190734863
epoch 7000 -- loss 2.2651939392089844
epoch 8000 -- loss 2.091233253479004
epoch 9000 -- loss 1.9466761350631714
epoch 10000 -- loss 1.8241318464279175
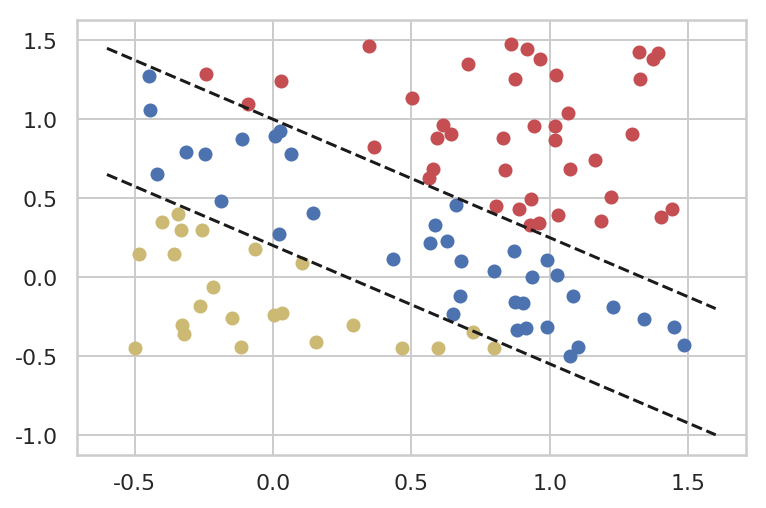
for epoch inrange(1, epochs + 1): y_hat = model(x_train) loss = F.cross_entropy(y_hat, y_train) optimizer.zero_grad() loss.backward() optimizer.step() if epoch % 1000 == 0: print("epoch {} -- loss {}".format(epoch, loss.data))
epoch 1000 -- loss 0.6635385155677795
epoch 2000 -- loss 0.5513403415679932
epoch 3000 -- loss 0.4890784025192261
epoch 4000 -- loss 0.44675758481025696
epoch 5000 -- loss 0.4151267111301422
epoch 6000 -- loss 0.39017024636268616
epoch 7000 -- loss 0.369760125875473
epoch 8000 -- loss 0.35262930393218994
epoch 9000 -- loss 0.3379631042480469
epoch 10000 -- loss 0.3252090811729431